From the period of our ancestors, man has been consistent in trying to improve the quality of his life (Burges 28). Such a direction has led to the development of basic tool forms; which were used by our ancestors for performing basic tasks such as digging and cutting (Burges 28). At this early stage, man was still utilizing a lot of physical energy while operating the early forms of machines that he had developed. With the discovery of other forms of energy like electricity and fuel energy, a stage was set for the development of a new generation of machines that required a very limited input of human energy (Burges 28). However, at this stage, there was still a wide scale monitoring of machine processes by man. To reduce the role of man in machine processes, a generation of automated machines was born. The main purpose of automation has been to reduce the role of man (mental and physical participation of man) in machine processes. A limitation of human participation in machine processes has been implemented through the incorporation of self monitoring mechanisms in machine systems. In this direction, there has been a need to develop machines that have human like aspects for the purposes of self learning and control. The field of “learning machines” has therefore been growing considerably in the past two decades. Such machines are capable of utilizing circumstances that they have encountered in the past to improve on their future efficiency (Burges 28). As it will be seen in this paper, such a system has numerous benefits that cannot be overlooked by machine designers. An important direction that has emerged in the design of learning machines is the aspect of multi-view learning. In multi-view learning, It is possible for a machine to view (understand) an input in a multi-dimensional manner (Burges 28). With the development of system management frameworks that utilize relational databases, some scientists have suggested the combination of multi-view learning with relational database for the purpose of increasing the capabilities of machine learning. In this literature review, a range of developments in the field of machine learning and multi-view learning in relational databases has been considered.
Machine learning can be understood as the process in which machines improve their capacities to function more effectively and efficiently in the future (Nisson 4). Such machines are therefore able to adjust their software programs and their general structure for the purposes of improving on their future performance (Winder 74). Such changes in the program and structure of machines are catalyzed by the environment in which the machines operate (Nisson 5). Machine learning is therefore an imitation of human intelligence where machines acquire some form of learning from their environment (Nisson 5). The environment of learning consists of a machine input, or a piece of information that a machine can respond to (Winder 74). Among the forms of learning that a machine can undergo includes a process of updating its database information dependant on the kind of inputs that it gets from its environment (Kroegel 16). The form of learning that has just been described above has inspired less interest from professionals in the machine learning field (Nisson 6). What is of more interest to professionals in machine learning are impressive learning processes such as it may occur when say a machine that is capable of recognizing the voice of some one is able to perform better; after recognizing repeated samples of speech from an individual. Therefore, we can think of machine learning as the process in which adjustments are implemented in the mechanism of machine actuators (Implementers of given instructions) that performs duties (Kroegel 16). Such a mechanism of a learning machine is usually embedded with a form of intelligence (Nisson 7). Examples of duties that are normally performed by intelligent machines include activities like the recognition of voices, sensing of parameters in the physical environment, predictive capacities among many others (Nisson 8).
Many benefits can be accrued from the process of machine learning (Blum 92). An obvious benefit that has an origin in machine learning includes a possible capacity for humans to comprehend how learning occurs in man; hence, finding an application by psychologists and educationalists among others (Blum 92). When it comes to the field of design and manufacture of machines, very important benefits can be accrued from machine learning (Blum 93). Any engineer that has specialized in machine design is aware of the challenge that he/she may face while trying to develop a concise relationship that maps inputs into predetermined outputs (Blum 94). Although we may therefore know about the outputs that we might get from a given sample of inputs, we may be unable to understand the function that will generate outputs for our system (Blum 94). One of the best ways that we can think of in solving the problem of understanding machine functions is to allow for a versatile system of “machine learning” to operate (Kroegel 20). By adopting the machine learning approach, we are able to design a machine with an inherent system that can approximate for some inputs for the purposes of giving us forms of outputs that are useful to us (Blum 95). Moreover, we may not be able to understand and therefore design for a complex web of interrelationships that generate machine outputs (Blum 96). Adopting machine learning helps in resolving the challenge of understanding complex interrelationships between outputs and inputs while generating expected outputs for us (Nisson 7). It is also true that the projected environment in which a machine will operate on cannot be fully understood by a machine designer at the stage of designing a machine. Indeed, an environment in which computer embedded machines operate in is bound to change considerably with time (Nisson 8). Since it is not possible go design for each and every change that will occur, developing learning machines is obviously an excellent approach to undertake (Nisson 8).
In the process of developing and improving on machine learning, “machine learning” engineers have adopted several approaches in obtaining sources of information on machine learning (Widrow 273). Among the important information sources that are applicable in machine learning include statistics
(Widrow 273). Among the challenges that have been encountered in the statistical approach is a difficulty in determining data samples that should be adopted due to non uniformity in probability distributions in data samples (ReRaed 630). Such a problem has been extended to make it impossible for a determination of an output that is governed by an unknown function; therefore, making it impossible to map some points to their new positions (ReRaed 630). Machine learning itself has been adopted as an approach in resolving the problems that are encountered while dealing with statistical sources (Nisson 7).
Another approach that has been adopted in machine learning includes the use of what are commonly referred to as brain models (Nisson 8). Here, use is made of elements that have a complex relationship that is non- linear (Dzeroski 8). The non-linear elements that are employed in machine learning reside in networks that approximate those (real) that are inherent in the brain of humans-neural networks (Dzeroski 8). On the other hand, in the adaptive control approach, an attempt is made to implement a process that has no clear elements; therefore, necessitating a need of estimating these unknown elements for the process to complete (Nisson 12). In adaptive control approach, an attempt is made to determine how a system will behave despite the presence of unknown elements in the system (Dzeroski 8). The presence of unknown elements in a system is mostly inherent from unpredictable parameters that keep changing their values in some systems (Bollinger and Duffie, 1988). Other approaches that have been used in the study of machine learning include the use of psychological models, evolutionary models and the use of what is commonly known as artificial intelligence (Nisson 12).
There are two kinds of environments in which the process of machine learning can occur (Dzeroski 6). The first environmental setting of machine learning is commonly referred to as supervised learning (Dzeroski 6). Here, there is at least some form of knowledge on the kind of outputs that we expect from a given source of inputs (Dzeroski 6). Such knowledge is obtained from an understanding of a function that governs a sample of values in a set that contains the data that we wish to train (Nisson 13). We therefore estimate that we can obtain a relationship that governs the sample that contains a set of values that we wish to train; consequently making the outputs of a given function true to the training set (Nisson 14). A simplified example of supervised learning includes a process such as curve-fitting (Nisson 14).
Another kind of environmental setting in which machine learning can occur is unsupervised learning (Muggleton 52). Here, unlike in supervised learning, we only have a sset of data samples that we wish to train, but we don’t have a function that will map the inputs in the available set to specific outputs in a way that we can determine (Muggleton 52). A challenge that is therefore commonly encountered while handling this kind of trainings sets is a difficulty in subdividing the set into smaller sets so that we can understand the outputs (Muggleton 52). Interestingly, this kind of a challenge forms part of the machine learning process (Muggleton 52). Therefore, the value that is obtained from a given function is related to a specific subset that takes in certain inputs (input vector) (Muggleton 52). Unsupervised learning has found a lot of applicability in forming classification systems whereby classified data is understood in a more useful way (Muggleton 52). As it is normal, there are many instances where both supervised and unsupervised learning systems exist in parallel (in machine learning systems) (Muggleton 52). In designing a learning system, it is normally appropriate to try and improve an existing function (Muggleton 52). This type of learning is normally referred to as speed-up learning (Nisson 14).
It will be useful to consider a number of important parameters that are commonly used in machine learning (Nisson 14). Among the parameters that are used in machine learning is Input Vectors (Input Sets) (Nisson 14). An input vector may contain input elements that are of different natures (Nisson 14). Among the types of inputs that may be found in an input vector include the following: real numbers, discrete values and categorical values (Nisson 14). An example of a categorical type of input is information on the sex of a given person (Nisson 14). Such information can be represented as either male or female. Therefore, a given individual can have a representative input vector that is of the following format: (Male, Tall, History) (Nisson 14).
Another important parameter that is useful in the study of machine learning is the output parameter (Nisson 15). In some instances, an output can take the form of real numbers (Nisson 15). However, in other cases, the output of a learning machine may take the form of categorical values (Nisson 15). Here, the resultant output from a learning machine is used to classify the value of its output to a given category (Nisson 15). Such an output is known as a categorizer; consequently, such an output may represent a label, a decision, a category or a class (Nisson 15). An output that is in a vector format may include both categorical values and numbers (Nisson 15).
Another parameter that one needs to understand in machine learning is training regimes (Nisson 15). Normally, Learning machines contain a trainable set of data (Nisson 15). The batch method is one among other possible approaches that can be employed in training the data set (Nisson 15). Here, all the elements in the set are applied in implementing a given function at the same time (Nisson 15). On the other hand, the incremental approach allows the operation of a given function on each member of the set separately. As a result, all the elements that are contained in the trainable set are iterated through a given function in a one at time arrangement (Nisson 15). The incremental learning process can occur in a predetermined sequence, or randomly (Nisson 16). In a common arrangement that is known as an online process, operations are performed on elements depending on their availability (Nisson 16). Therefore, operations are performed on the elements that have updated their availability (Nisson 16). Such a system of operation is especially applicable when a preceding process inputs an oncoming process (Nisson 16). As in any other machine process, a machine learning process can be influenced by Noise. In one type of noise, the function that operates on the trainable set is impacted (Nisson 17). On the other hand, there is another type of noise that impacts on the elements that are contained in the input vector. For an efficient system of machine learning, it is important to evaluate the effectiveness of an implemented learning process (Nisson 17). A common approach that is utilized in evaluating supervised learning is to use a special comparison set that is generated for the purpose comparison (Nisson 17). Here, the outputs of the comparison set are compared with the outputs of the learning set in order to evaluate how effective the learning process has been (Nisson 17). Moreover, it is important to appreciate that for any learning activity to occur, an element of some form of bias is necessary (Nisson 18). For example, in machine learning, we may decide to restrict our functions to a small set of values (Nisson 18). We may also decide to restrict our functions to quadratic functions for the purpose of achieving the results that we desire (Nisson 18).
Dietterich Thomas has described machine learning as a study of diverse approaches that are employed in computer programming for the purposes of learning (Thomas 7). The purpose of machine learning is therefore to solve special tasks that cannot be solved by normal computer software (Thomas 7). There are several examples of complex tasks that cannot be solved by normal computer software (Thomas 7). For example, there is a need to determine machine breakdown in factories through the employment of systems that scan sensor outputs (Thomas 7). A learning machine is therefore able to learn how recorded sensor inputs have related with machine breakdowns; therefore, creating an accurate system that can predict machine breakdowns before they occur (Thomas 7).
In another way, we know that as much as human beings have some inherent skills such as an ability to recognize unique voices, they cannot really understand the step of processes that they have followed in employing their skills (Thomas 8). Such a reality has limited the capability of humans to employ their skills on some unique situations in a consistent manner (Thomas 8). By giving a learning machine some examples of sample inputs and corresponding outputs, a learning machine can take over to give us a set of consistent results in unique circumstances (Thomas 8). Moreover, some parameters in the environment of a machine will keep changing in a non predictable manner such that it is only wise to employ machine learning in such environments (Thomas 8). Still, it has been desirable to tailor computer applications to the specific need of an individual for effective functioning; hence, drawing a need of machine learning in the process (Thomas 8). Examples of areas with characteristics that have been described above where machine learning has found an array of applicability include statistical analysis, mining and psychology among others (Thomas 8). For example, when performing data mining, what we normally try to do by the help of learning machines is to collect important sets of data that are useful to us (Thomas 8).
The process of learning can be grouped into two categories: empirical and analytical learning. The distinct difference in analytical learning and empirical learning is that while empirical learning relies on some form of inputs from the external environment, analytical learning is non reliant on the external environment (Thomas 9). At times it may not be easy to distinguish between empirical learning and analytical learning (Thomas 9). Take something like file compression for example (Thomas 9). As it can be seen, such a process would involve both empirical and analytical learning (Thomas 9). Normally, the process of compression involves the removal of data that is repetitive or irrelevant in a file (Thomas 9). Such information can be retrieved from a kind of a dictionary when it is required again (Thomas 9). Such a process can only occur by studying the how sets of file systems are organized hence a kind of empirical learning (Thomas 9). On the other hand, the process of compressing and recompressing files is inbuilt; and therefore it does not require information from the external an environment; hence, a type of analytical learning (Thomas 9).
Multi-view learning with relational Database
Today, most systems that are used in data storage employ the use of relational databases (Guo 5). Here, it is possible to store information that is interrelated through the use of foreign keys (Guo 5). A challenge that has been encountered is the difficulty n storing mining information in the format of relational databases (Guo 5). Such a challenge has mostly arisen with the nature of mining approaches that employ the use of single dimension data (Guo 5). Examples of such approaches include the use of neural networks (Guo 5). A difficult task that is therefore presented in this kind of arrangement is the tedious effort of converting the multi dimensional relations that are inherent in mining data into a one dimensional format (Guo 5). To overcome this challenge, a number of applications such as Polka [14] have been developed to map mining data into a single dimension (Guo 6). One setback that has arisen from these converting applications is the loss of relational information in mining data (Guo 6). A considerable amount of information is therefore lost even as a data baggage is created (Guo 6).
An important approach that is emerging in the resolution of mining data problems is multi-view learning (Perlich 167). The approach of multi-view learning has been useful in tackling a range of issues in our world (Guo 6). Consider a multi-view data such as [4, 11, 14, 21] (Guo 6). We may retrieve this kind of information in the above data such that: the retrieval of data information [4], the recognition of voice [11], signature identification [21] (Guo 6). It is therefore possible to ingrain the idea of relational database in multi-view learning. Here (Multi-view learning), it is possible to obtain a specific view that is desired depending on a set of unique features that is present is a training set, say [14] (Perlich 168). It is therefore possible to learn diverse concepts from each of the views present in multi-view data (Perlich 168). Following this process, all the concepts that have been learned are then combined to form the learning process (Perlich 168). To understand multi-view learning, consider a system that may be employed to group emails dependant on their contents and subject (Perlich 168). While one system will learn to classify emails depending on their subject, another system will learn to classify emails dependant on their content (Thomas 5). Finally, learned concepts of the content learner and the subject learner are combined to perform the final classification of emails (Thomas 5). Therefore, for a multi-view system with n views, It is possible to obtain n related relationships that can be employed in multi-relational learning (Perlich 168). For the application of multi-relational learning in mining, we are able to obtain some patterns from multidimensional relationships (Perlich 168). For each of the relationships, there is some specific information that is learned (Perlich 168).
Let us consider another kind of a problem where we need to identify whether a banking customer is a good or not (Guo 10). Form the bank’s database; we can obtain relational data about the customer (Guo 10). We can for example obtain relational data about the name of the customer from the client relation, credit card details from the account relation and so on; thus, determine whether the customer is good or not (Guo 10). An important thing to note here is that for each of the database relations, there are diverse views on the customer on whether he/she is good or not; therefore, contributing to the final concept of information that will be learned about the customer (Guo 10).
In multi-dimensional learning, a set of instructions in the form of multi-view classification (MVC) is employed (Guo 10). The purpose of multi-view classification is to use the framework of multi-view learning so as go carry out processes on the data of multi-relation database in data mining (Guo 10). The description of the multi-relational process can be understood as follows. In the relational database, there are identifiers for each of the characteristic found therein (Guo 10). These characteristics are linked to other dependent characteristics by the use of foreign keys (Guo 10). Once the above process has completed, the second stage involves attributing specific functions to each of the characteristic that has been linked to a specific identifier through a foreign key linkage (Guo 10). Such a direction is helpful in handling each of the many inter dependent characteristics that are present in concerned data (Guo 10). The next stage involves using each of the foreign assigned characteristics as an input to a unique multi-view learner (Guo 10). In the next process, normal data mining approaches are applied such that they obtain each of the intended concepts available from each of the present data views (Guo 10). The above process precedes the final stage where learners used in the development of a useful model that contains the needed information (Guo 10). Therefore, a MVC method that works in a framework of multi-view learning can be used to incorporate normal mining data in a relational-database (Guo 10).
Having described the above process in brief, let us consider important concepts that have been employed in the above process (Pierce 1). It would be useful to start by understanding relational databases (Pierce 1). In a relational database arrangement, there are sets of various tables represented as follows [T1, T2, T3……](Pierce 1). There is also a set that represents interrelations between the tables (Pierce 1). In each set, like in a normal database management system (Pierce 1), each table has at least one unique key called the primary key (Guo 16). This primary key represents a unique attribute that is common to all elements in a given table (Pierce 3). Other attributes that can be found in a table apart from those that have been underlain in a primary key include descriptive attributes and foreign attributes (Pierce 3). Foreign attributes are used to link table elements to attributes that are present in other tables (Nisson 23). Tables in a relational database are therefore linked by the aid of foreign keys (Pierce 3).
Having understood relational databases, let us now move on to understand the process of relational classification (Pierce 4). An important approach that has been employed in machine learning is the classification of activities for the purpose of effecting targeted learning (Pierce 4). For example, consider a situation in which we intend to obtain a unique relation (U) in a given database (Pierce 4). Let us also say our unique relation (U) has also a unique variable (Y) (Pierce 4). Here, the purpose of implementing relational classification would be to obtain a function F that would give an output from each of the elements in a given table (Pierce 4). The relationship that has be described above can be represented in the function below:
F = Ptarget.key + Y + A(Pk) – Akey(Pk)……………………………………………..(i)
Akey(Pk) are the key elements of table Pk.
We can therefore go ahead and analize the process of relational classification as it has been described above (Pierce 4). The figures below (In figure 1) represent table interrelationships and can help us to understand the process of relational classification (Guo 17). Looking the target table called loan table, attributes therein include account-id, status, among others. The important row in this table that will be targeted is loan-id (Guo 17). The intended concept for learning is the status. We can see that the target table has been linked to other foreign tables including the order table (Guo 17). It is from the order table that we wish to create training views (Guo 18).
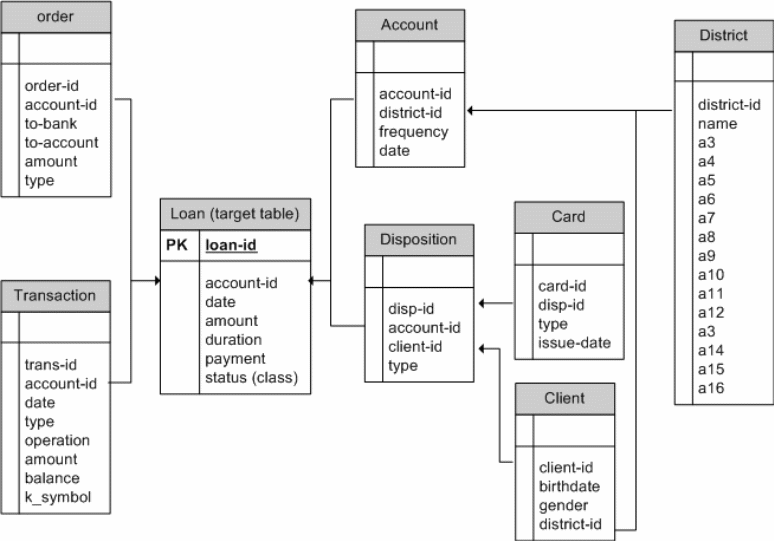
Looking at how the arrow has been directed between the target table and the order table below, we can see that the account-id element has been linked through a foreign key (Quinlan 19). Each of the elements that are linked to the target table through the account-id will therefore consist of the loan-id (it is a primary key and therefore inherent in all fields in a table) and the status element (Intended concept of learning) (Quinlan 19). In addition to the above fields, the account-id would also consist of all the other fields (account-id, to-bank, to-account, amount and type) that are present in the order table with the exception of the order-id field (Quinlan 19). In the algorithm of SQL, performing the operations that have been mentioned above would consist of the following (Quinlan 19). One would be required to create a table object with the mentioned parameters from the loan table and the order table (Quinlan 19). The determining condition for the creation of the objects would be limited to situation where the account-id from the order table is equivalent to the corresponding account-id from the loan table (Quinlan 19).
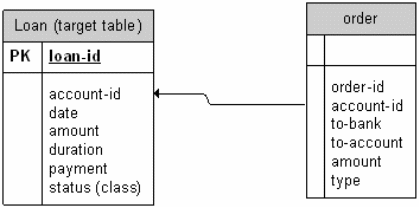
Let us now describe the process of multi-view learning again for a better understanding. For each of the learners that are present in a multi-view learning environment, the learner is given a group of data for the training purpose. To understand how this arrangement applies to multi-relational classification, we need to consider an intended concept for learning; which is contained in the targeted table (Quinlan 19). The first thing that occurs in a multi-view environment is the relay of the intended learning concept to all other relations that have been linked to the targeted table through foreign keys (Quinlan 19). All the elements that are required by the implementing function from the target table will also be transferred to the other tables that have been linked to the target table through the aid of foreign keys (Quinlan 19).
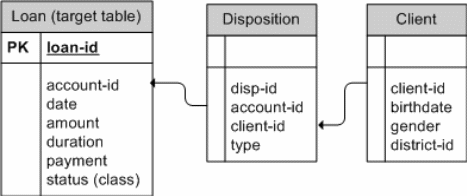
Let us now consider another kind of a situation in the tale above (Pierce 10). The target table remains as the Loan table (Pierce 10). On the other hand, the intended training data is obtained in a different way from the previous example (Pierce 10). From the client table, intended data for training is no directional foreign keys linking it with the target table (Pierce 10). What the client table has done is to link with the disposition table through the element of client-id (Pierce 10). On the other hand, the disposition table has linked to the target table through the aid of the account-id element (Pierce 10). With multi-view relationship in mind, this arrangement can be described as follows (Pierce 10). Basically, elements with client-id from the client table have been connected to elements with client-id in the disposition table (Pierce 10). On the other scenario, elements with elements with account-id in the disposition table have been linked with their counterparts with the same id in the target table (Pierce 10). Intended data for training will therefore consist of two elements (birthday and gender) from the client table in the first place (Pierce 10). The other two elements (loan-id and status) are obtained from the target table (Pierce 10). In an SQL algorithm the above process can be implemented in the following way. First, we create an object of four elements from the client, disposition and client tables (Pierce 10). We then set two preconditions that will act as a threshold in the formation of the table object (Pierce 10). First the account-id has from the disposition table needs to be equivalent to its corresponding account-id in the target table (Pierce 10). Likewise, the client-id from the client table needs to correspond to its counterpart in the disposition table (Pierce 10).
In more difficult data applications such as those that are encountered in data mining, there is a complex web of interrelationships between tables (Data) (Rijsbergen 42). Some of these relationships can be broken down to one table with many arrows linking to it, while others can be broken down to many interconnecting links (Rijsbergen 42). What we have examined above is a simple case of many connections linking to one table through the aid of the primary key (Rijsbergen 42). It is possible to obtain a range of outputs from this kind of interconnection (Rijsbergen 42). A difficulty is therefore presented in identifying the correct output (Rijsbergen 42). An approach that has been undertaken to resolve the above challenge is to employ the use of aggregation functions in a MVC setting (Rijsbergen 42). What an aggregation function does is to unify all related outputs into a single output. Therefore, an aggregation function acts like a summary of properties that have been presented in a range of outputs in a single output format (Nisson 22). In unifying a range of outputs into a single output, an aggregation function employs the use of the primary key that is present in the target table (Rijsbergen 42). Each of every table that is formed afresh is acted upon by the aggregation function to summarize its related properties in a single output format (Rijsbergen 42). The resultant output is what is employed for multi-view training (Rijsbergen 42). All the resultant multi-view outputs are employed to train a corresponding number of multi-view learners (Rijsbergen 42). Examples of aggregation functions that are commonly used on data include COUNT, MAX and MIN (Rijsbergen 42).
Since it is the MVC algorithm that is used in linking multi-view learning with relational databases, it is important to evaluate the working of MVC algorithm (Guo 32). The approach that has been presented has therefore been intended to allow the framework of multi-view learning input data from relational databases (Guo 32). There steps are normally involved in a typical MVC algorithm (Guo 32). First, a group of training data is obtained from a relational database (Guo 32). Here, just as we had seen in relational classification, groups of data for multi-view training are obtained from a relational database source (Guo 32). Such a process is normally implemented by the aid of foreign key connections (Guo 32). Therefore, elements in the target table are associated with elements in other tables through foreign keys (Guo 32). Moreover, aggregation functions are applied to unify a range of related outputs in the many to one relationship (Guo 32). Secondly, multi-view learners are set in motion to ingrain the intended concept in every of the resultant data groups (Guo 32). Consequently, trained learners that have been created in the second step are employed in creating an information model with useful knowledge(Guo 32).
The above is a summary of the three important steps in the implementation of MVC algorithm (Srinivasan 300). Let us now evaluate the above steps in more detail. In the first step, we intend to create a group of data that will be used for training purposes (Srinivasan 300). This group of training data is obtainable from relational databases (Srinivasan 300). A group of multi-view data for training is created for each element in the target table based on relationships from other tables (Srinivasan 300). Since it is paramount to provide sufficient information for each of the multi-view learners, the above approach of relating all elements in the target table to information from other tables is important (Srinivasan 300). Once this process has completed, aggregated functions are then employed to solve the problem of one to many relations that may exist between other tables and the target table (Srinivasan 300). For example, in figure one; there are about seven associations with the target table from other tables (Nisson 17). In this kind of a scenario, the MVC will develop eight groups of training data in a multi-view format (Srinivasan 300). Here, one of the training data groups will be created for the Loan table while the rest will come from other tables (Srinivasan 300). Aggregated functions will therefore present a kind of a summary from all of the multi-view data (for data training) (Sav 1099). As aggregated functions act on the multi-view relationships, some elements from the tables are unified to create training data groups (Sav 1099). In the end, it is the elements that have direct and indirect associations through foreign keys from other tables to the target table that are selected (Sav 1099). Therefore, it often happens that once aggregated functions have acted on relationship data, the numbers of data training groups are decreased (Sav 1099).
The second step that is implemented in a typical MVC algorithm is the creation of learners to learn from the trainers that have been formed in the previous stage (Sav 1099). The learning process is therefore started here with an emphasis on the intended concept for learning (Vens 124). It is important to understand that each of the learners will form a unique theory from a group of training data (Vens 124). Therefore, a range of perspectives from different learners is given; hence, allowing for a system of checking and unifying these diverse perspectives from learners in the final step (Vens 124). In the final step of the MVC algorithm, we have a final learner (meta-learner) that gets inputs from a range of learners from the previous step (Nisson 30). However, before the perspectives of learners are used by the meta-learner, they first undergo a validation process (King 337). Here, a system is used to check for the accuracy of the perspective that has been presented by each of the learner (King 337). If a learner is found to have an error that has surpassed the 50% percent mark, such a learner is ignored (Nisson 28). Therefore, the performance of the learners is thus evaluated to ensure that the ongoing information to the meta-learner is accurate (King 337). Once the perspectives of the learners have been evaluated, validated perspectives from the learners are fed to the meta-learner (King 337). The work of the meta-learner is to unify all the perspectives from the learners for the purpose of creating a useful model of information (King 337). Each of the perspectives that are presented to the meta-learner by a learner consists of a unique judgment in predicting an output (King 337). Let us consider the eight tables in figure one. Our task is to find out the truth about the following situations on the condition (status) of a loan: whether a loan is good and unfinished, good and finished, bad and unfinished, bad but finished (Guo 14). In our target table, there are over six hundred possible records that contain an attribute that indicates the condition (status) of a loan (Guo 32). As it has been indicated in figure 1, all of the tables have some form of association with the target table (Guo 32). Such a relationship has been underlain by direct and non direct foreign key relationships (Viktor 45). Therefore, all the other tables have stored some form of information about the target table (Viktor 45). We can therefore consider three learning activities that can be undertaken here. First of all, we need to find out whether a loan is bad or good based on about 234 possible finished conditions (Guo 32). Secondly, we also need to find out whether a loan is either bad or good based on about 682 possible records irrespective of the finished status (Guo 32). Finally, we employ the use of the transaction table to remove some positive relationships in the target table in order to balance and enhance the learning process (Guo 32).
One of the boulder challenges that have emerged in the study of machine learning is the difficulty of labeling data for the purposes of training (Muslea 2). Such a process is time consuming, tiring and may also result in inaccuracies (Muslea 2). Muslea has argued that it is desirable and possible to reduce and/or eliminate the task of data labeling in machine learning applications (Muslea 2). In multi-view learning, it is possible for different views of a learning machine (of multi-view learning type) to perceive a targeted concept in isolation (Muslea 2). For example, by applying the use of either an infra-red sensor or a sonar sensor, it is possible for a robot to navigate around an approaching obstacle (Muslea 2).
An important approach that is desirable in avoiding the use of data labeling for learning machines is Co-testing (Muslea 4). In Co-testing, focus is placed on the usefulness of mistake learning (Muslea 4). In a situation where views present a range of conflicting outputs, the false view will automatically present mistakes in the system (Muslea 4). Therefore, the system learns to adopt the correct label for targeted concepts by referring to the database of mistakes that it has made (Witten 13). Through Co-testing, machine learning has moved towards the lane of active learning.
The active learning process in Co-testing is presented in the following way. At the initial point, the system has an inbuilt array of a few instances where it can infer to label a targeted concept in each of its views (Witten 13). For a situation where, its views output a non expected outcome, a user inputs a new label for that concept label (Muslea 17). Once this has been achieved, the co-testing system will automatically entrench the new labels into it database for use in identifying and labeling other views in the future (Muslea 17). What transpires in this process is that for instances where learning views of a learning machine predict conflicting labels for a targeted concept (Yin 108), then, it is true that one or more of the machine learners has made a mistake in interpreting the learned concept (Muslea 17). Therefore, the task of identifying the label is taken to a user for identification (Muslea 17). Once a user identifies and authenticates a targeted concept, then, the view that had erred in identifying the label is provided with correctional information (Muslea 17). However, it is important to note that foreign parameters that are non desirable in a learning setting such as noise are capable of influencing the learning process (Yin 108).
It is possible to extend the use of Co-testing so that the system can be able to update its database without referring to the user (Wolpert 244); hence, learn to identify new labels automatically (Muslea 17). Such a type of a system that is able to combine both automatic learning and human intervened learning known as a Co-EMT system (Muslea 17). For a simplified understanding of the Co-EMT system, we can understand the system as composition of the Co-testing system and the Co-EM system (Muslea 17). In the first place, the system applies an approach whereby unknown labels are identified in accordance with how other views in the system understand the concept (Wolpert 244). Thereafter, it updates its learning database in each of its views through training on the understanding of the concerned concept from the other views (Muslea 17). An obvious advantage that is presented to the counterpart of the CO-EM system in a Co-EMT arrangement is that the Co-EM is now able to identify unique data that has been encountered by the system unlike the previous arrangement whereby it identified labels in a non predictable manner (Muslea 17).
As in any other arrangement of multi-view learning, one cannot escape the stage of data validation as a way of checking on authenticity for the purposes of minimizing errors; hence, form a model that would provide useful information for the system and its users (Watkins 54). Considering that a Co-Testing system consists of many targeted concepts that are not labeled, a more difficult challenge is presented at the stage of data validation (if one was to employ the normal approach that is employed in data evaluation) (Watkins 54). In noting that most validation procedures employ the use of positive and inverse learning for a given view, and that such a process is not required at all times, Muslea has suggested a new system that can be used to authenticate data (Muslea 17). Muslea considered unique instances whereby positive evaluations produced low accuracies as inverse evaluations produced high accuracies on a similar piece of multi-view data (Muslea 17).
In this direction, Muslea has suggested a new approach that can be used in the authentication of data: Adaptive view validation (Muslea 17). Basically, this type of a system is a kind of a meta-learner that incorporates previous circumstances and experiences in authenticating data to perform a data authentication task (Muslea 17). The inherent experience of the meta-learner is employed for one important purpose: to decide whether it is useful to incorporate available views from learners for effective learners (Muslea 17). Thus, a number of views from learners are considered as unnecessary or inadequate for the learning process (Muslea 17).
Conclusion
Due to its obvious benefits, machine learning has progressively incorporated into machine and manufacturing systems. In fact, forms of machine learning have existed for a long period of time before the birth of experts in machine learning. The current trend is not just to design machines with human like intelligence; the scope is wider as to design machines that can learn in a way that man has been unable to (Guo 22). As more and more knowledge on machine learning has built, an array of approaches in the design of learning machines has emerged. Among the approaches that have been utilized in the learning process of machines include the use of the statistical approach, the use of brain models, the use of neural networks and the use of adaptive control mechanisms among other approaches. With multi-view learning whereby machines have been installed with a capacity of learning from an array of different possibilities, the multi-view approach has especially been helpful in producing accurate outputs. Here, an array of outputs from a single input is possible because of the different views that are incorporated in learning machines. Since, it is possible to produce a single output from all the views by the use of approaches such as the method of aggregated functions, obtained outputs from learning machines are likely to be accurate(Guo 22). Also, since the design of learning machines has been partly driven by a need to supplement for human limitations, it is useful to use learning systems in analyzing complex data types such as those that are found in data mining (Guo 22). In this direction, an approach that has been laden with a lot of promise is the marriage of multi-view learning and relational databases (Guo 5). Such an approach has presented numerous benefits to the process of machine learning. In one way, many people are already familiar with the system of relational databases and therefore, adopting relational database in multi-view learning presents a simplified approach in machine learning. Moreover, the use of MVC algorithm and aggregated functions has presented an opportunity of obtaining useful models from complex data types such like mining data (Guo 22). It is interesting to note that there has been a consistent array of new developments in machine learning. Among the significant directions that have originated in machine learning is the use of Co-testing approach in understanding labels (Muslea 2). It is also interesting to make an observation that we may eliminate non useful views during data analysis for the development of models (Muslea 10). It can therefore be expected that more effective and fruitful tools will continue to emerge in machine learning for the creation of more efficient learning machines.
References
Blum, Mitchell Combining Labeled and Unlabeled Data with Co-training. New York: McMillan, 1997. Print.
Burges, Cole “A Tutorial on Support Vector Machines for Pattern Recognition.” Data Mining and Knowledge Discovery 2.1, 1994: 121-168. Print
ReRaed, Muggleton. “Inductive logic programming: Theory and methods.” Dzeroski, Simon. “Multi-relational Data Mining: An Introduction” ACM SIGKDD Explorations, 5(1), 2003: 1-16. Print
The Journal of Logic Programming 20.5, 1994: 629-680. Print
Guo, Hongyu. Mining Relational Databases with Multi-view Learning. Ottawa: University of Ottawa, 2003. Print
King, Camacho. “Proceedings of the Fourteenth International Conference on Inductive Logic Programming.” Springer-Verlag 13.4, 2004: 323-340. Print
Kroegel, Mark “Multi-Relational Learning, Text Mining, and Semi-Supervised Learning for Functional Genomics.” Machine Learning 57.8, 2004: 61-68. Print.
Muggleton, Feng. Efficient induction of Logic Program Tokyo: Ohmsma, 1993. Print.
Muslea, Alexandru. “Active Learning with Multiple Views” New York: University of Southern California Press, 1993. Print
Nisson, Nils. Introduction to Machine Learning London: McMillan, 1995. Print
Perlich, Provost. Aggregation-based feature invention and relational concept classes Washington, D.C. 2003: Mayfield, 2000. Print.
Pierce, Cardie. Limitations of co-training for natural language learning from large Databases McMillan: New York, 2005. Print
Quinlan, Cameron “A midterm Report.” Vienna, Austria: European Learning Press, 1993.
Rijsbergen, John. Information Retrieval. London: Butterworths, 1979. Print
Sav, Ballard “Category learning from multimodality.” Neural Computation, 10.5 1998: 1097-1117. Print
Srinivasan, Bristol. “An assessment of ILP-assisted models for toxicology and the PTE-3 experiment.” London: European Leaning Press
Thomas, Dietterich Machine Learning. Oregon: Oregon University Press, 2003.
Vens, Assche. First order Random Forests with Complex Aggregates. New York: McMillan, 1997. Print
Viktor, Herbert. “The CILT Multi-Agent Learning System” South African Computer Journal (SACJ) 24.3, 1999: 43-48.
Watkins, Simons. “Learning from Delayed Rewards” PhD Thesis, University of Cambridge: England, 1989.
Winder, Ronald. “Threshold Logic.” PhD Dissertation. Princeton University: Princeton press, 1962. Print
Widrow, Stearns. Adaptive Signal Processing Englewood: Prentice-Hall, 1999. Print
Witten, Frank. Data mining – practical machine learning tools and Techniques with Java implementations. London: McMillan, 2002. Print
Wolpert, David Stacked Generalization, Neural Network. McMillan: New York
Yin, Han. Cross Mine: Efficient Classification across Multiple Database Relations. London: European Learning Press, 2003. Print.