Why organizations should spend time gathering secondary data prior to undertaking primary research
Statistical research is one the most important roles of an organizations. This kind of research is mainly useful in decision making. It is important because of the expected results from given activities that a company or an institution may desire to undertake. It will not be prudent if this topic is discussed without a detailed understanding of the terms statistics, statistical methods and statistical research and its application.
Statistics is the process of data collection, data analysis and interpretation of the data and making meaningful conclusions and generalizations. Statistics is a skill that was developed to reduce the difficulties that people faced when making certain decisions. For instance, a drug manufacturer may want to market tropical disease drugs but information may be required to ascertain on the areas classified as tropical, how often these diseases recur and how many people are affected by the diseases each time. The collection, simplification, analysis and conclusions made based on the collected information using accepted methods are what entail statistics (Baines 2002, p. 23)
Again, Statistical methods as the phrase suggests are techniques that are generally accepted for use in data collection, interpretation and analysis. Hofferth (p. 1) states that, “…statistical analysis too often has meant the manipulation of ambiguous data by means of dubious methods to solve a problem that has not been defined.” These methods involve ways for collecting, collating and analysis which lead to making conclusions and generalizations.
If the target population allows for a single variable, then one can use uni-variate methods and if it does not give meaningful analysis then one must use multi-variate methods. These methods may include sampling methods such as cluster sampling, multistage sampling and snow ball sampling methods. Methods of collecting data could be done using by questionnaires, interviews or mini census. Analysis can be done by use of measures of central tendency, frequency distributions and the Orgive curve (Patzer 1995, p. 241). Other advanced methods could be used.
Advantages, disadvantages of secondary data and how the disadvantages can be minimized
Before any statistics is done it is important to plan earlier. Planning involves identifying the target population, methods to use, sources of data, and requirements and methodologies for analysis of data. Sources of data entail primary and secondary research sources. More often, secondary data is collected from known sources, while primary research data is collected to enhance the final findings and conclusions. It would be important for organizations to collect secondary data for good reasons while considering the negative effects that may come with that kind of data. The good reasons will be the rational thinking on why organizations need to collect secondary data before undertaking a primary research.
First, Secondary data will be useful because it is economical compared to primary data. Generally speaking looking for crude data, cleaning it and presenting it could be a very expensive procedure. But if the required data can be sourced from non-governmental organizations, government bureaus of statistics or commercial firms it would be cheaper. According to Hackley (2003, p. 33), “Even when secondary data is provided by a commercial firm, it would be less expensive compared to primary data because it is available on multi-client basis to a large number of users than being custom designed on a proprietary basis for a single client.” Any company would want to reduce cost of conducting research but maximize on the benefits of the results. Because of this, it is cheaper to collect data from secondary sources.
Secondly, secondary data can be collected within a very short time, therefore, increasing the speed of doing your research. For instance, if a researcher wants to collect data about the number of beer drinkers in each of the fifty four American States then it would take an enormous amount of time and resources to do a primary research. If this is compared to collecting data from each of the state statistics bureaus, then the amount of time that can be taken will be enormously decreased (Balakrishnan 1997, p. 57)
Thirdly, not all data can be collected by individuals or companies because of the nature of the information or by restriction of laws. For example, if one needs data of census, it would be a time consuming, expensive and may be not be allowed by the laws of certain countries. This means that, to get the information, one need to get it from the National Bureau of statistics. The question of availability makes the use of secondary data a very strong factor.
Finally, secondary data provides room for comparison. Data can be obtained from a number of commercial and non-commercial firms and compared accordingly. Since the data was collected independently, then the validity of the data can be based on the comparisons in terms of similarities or differences. The flexibility of the data collected will be high and hence it can be used for various purposes rather than the first intended use.
As much as the secondary data can be useful and readily available for analysis, some concerns must be put into consideration. According to Gil (1978 p. 522), he emphasizes that, “secondary data were generated for some purpose rather than to answer the research question at hand, care must be taken in their application.” The following are some of the challenges or rather limitations of secondary data.
The sources of secondary data vary widely to the extent that the researcher will be faced with the dilemma of choosing the most appropriate source. The researcher may want to choose the most reputable firm in the town, but depending on the day the data was collected the quality may be compromised. The researcher will have a tough job of deciding on the most appropriate firm and this may be a time consuming factor that was never anticipated.
Secondly, some of the free data firms may have collected the data for the wrong reasons. For instance, data collected by non-governmental organizations may be faced with the conspiracy of trying to ‘doctor’ the data in order to attract funds from philanthropists. On the other hand, governments can change the actual data to fit them to avoid negative publicity. Secondary data suffers the factors of being changed in order to distort the information to suit the person collecting the data (Walle 2001, p. 51).
Thirdly, data may lack accuracy. Why is accuracy compromised? The source of the data collected could be secondary; this means that that the secondary source of data might have been from another secondary source. There might be transfer of errors or even more mistakes caused during transcription and translation.
Fourthly, the secondary data may result to a poor fit because the data might have been collected for a different research question from the current question being analyzed. This may be caused mainly because of statistical issues such as poor interval of collection of data, poor data intervals and/or parameters. The data in question may not have been collected from the most representative sample. Errors of sampling may be transferred from one secondary source to another, hence resulting to a poor fit and hence wrong results (Wrenn et al. 2007, 91).
Without the threat of dubious business men, secondary data collected may have been collected over a very widely spread period of time but represented as current data because of the date of completion. Thus the secondary data may be outdated but given a more recent date. This may not reflect the situation at hand so that the research question is answered correctly. The credibility of secondary data is questionable to some extent, thus a lot of care must be taken before using or even deciding to collect it.
However, the above challenges can confronted in order to minimize errors that may be brought along with the secondary data. One most important activity that the researcher must do is to choose credible firms as the prime sources of data. After using a certain criteria to choose a firm then he/she can get the same kind of data from a number of sources. The reason for doing this is to compare the different data sources and settle on the most appropriate.
This will also enable the researcher consider using a different set of data and compare the results of both sources of data. If the results agree for two or more independent data sources then the researcher may make a more meaningful conclusion, otherwise he/she will have to question the integrity of the data sources. For the researcher to be sure that the secondary source of data is not secondary in itself, he/she must confirm that the data collected was primary (Stiefel 1990, p. 7). For good and reputable organizations, it would intend to give the actual facts about the data the researcher is about to analyze. This means that as a researcher, it is essential to seek for a lot of information as possible about the secondary data in question.
Government sources’ secondary data may however, have a number of choices to make though some type of data may be collected independently. This means that the researcher must try to find out whether there are other sources of the same kind of data. This will enable him/her avoid bias in the data in question. Overall, the researcher must be extremely careful in analysis, and in some extent required to get the data from the crude form and then convert it to tables that can be read easily (Urdan 2001, p. 344).
Discussion of information from Office of National Statistics
The information available on the website is considered to be secondary data if a researcher wants to set a new research question. The data is readily available, a very important factor of data analysis. This is an advantage because to get the information, you don’t need to move from the office. It facilitates speedy analysis because of it being readily available. The data as well is given in different format like csv extension which is comma delimited and can be used for analysis using different statistical packages including SPSS. The data also has a basic analysis to infer from, for example simple trends can be directly read from the graphs provided.
The information is divided to a number of basic sub-groups hence finer details of analysis can be achieved (Grossnickle 2001, 97). For instance, the total number of visitors is classified into regions, reason of travel, nights spent and total expenditure for the visitors. This means that if the research question concentrates on tourists then analysis can be done that includes only tourism visitors.
On the hand this might not be the right source of your data because of simple reasons. One, the data cannot be used to study individual behavior of each of the visitors. For instance a food company would need to know the kinds of food that majority of the visitors eat as they visit United Kingdom. In this sense the information may fail to help the researcher hence need to do a primary research based on the figures received from the Office of National Statistics. Two, the data might have included visitors that stop over for a few minutes at the airport, this number may not be useful for some marketing researcher whose products are not used at the airport (Johnson 2009, p. 303). A huge number of the visitors may provide redundant statistics to the researcher. This calls for more refined numbers which will make it necessary for a primary research to be done.
The data has been compressed into regions implying that the individuals have similar behavior, which cannot be useful to make some analysis that can be used to make particular conclusions about the visitors. Though the office provides for more aggregated data for the English regions to remedy this, the researcher may be interested with more than the English regions. The office as well gives the warning, “Figures for a number of regions are based on small sample sizes. It is not recommended to use data where the sample size is less than 30. Even if the sample size is above 30 the user may find it helpful to consider looking at three year averages rather than the results from a single year” (Fletcher 2001, p. 102). This implies that it may not be very useful to the researcher who wants a small sample for analysis.
But generally, the data will be very useful for multinational companies and corporations for planning a more detailed survey of the United Kingdom market for their products. It is also very useful for planning in most governmental departments within the United Kingdom. The data provided might be very good to every researcher interested with the United Kingdom but far and wide it is a very useful source of secondary data.
Current trends in tourism to the UK by overseas Visitors
The table below is extracted from the Office for National Statistics; it shows the figures of the number overseas residents’ in the United Kingdom by year.
Table 1: Overseas residents’ visits to the UK by year.
The graph below is extracted from the Office of National Statistics which shows the general trends in visits to the United Kingdom by year. The graph is specifically for those visitors whose purpose is holiday (tourism), all over the world, and to the whole United Kingdom.

The General Trend shows that there is an increase in the second and third quarters. The United Kingdom generally expects a higher number of visitors in the third quarter of the year. This is clear because of the trend in number of visitors having remained high in the third quarter of the year since 2004. Since the numbers may be affected because population increases implies that the number of visits may generally increase.
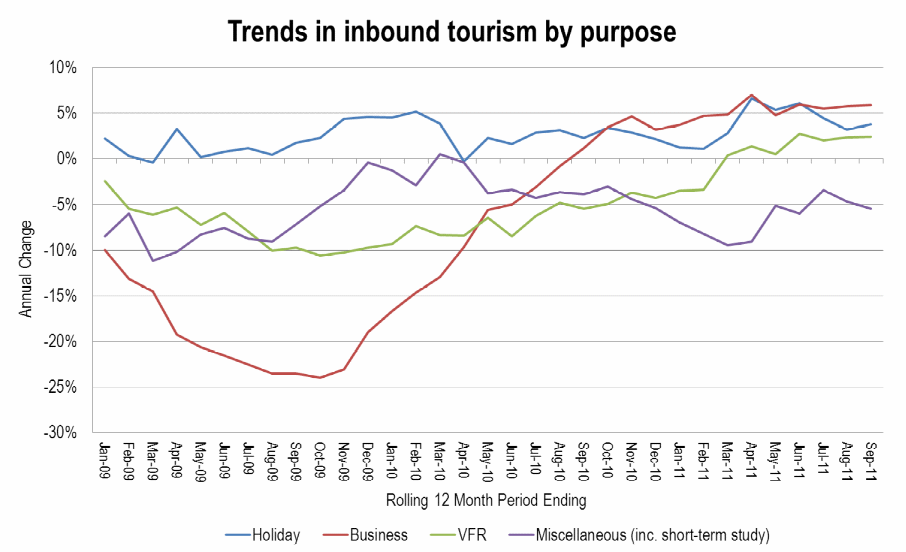
The graph below uses percentages which may give a correct reflection on how the number of visits may change over time. The graph is extracted from the visitbritain.org website. The graph agrees with the total visits graph, the highest number of visits is associated with holiday visits. And the general trend is that in the third quarter of each of the years visits increase. Business visits have a sharp increase which may be attributed to better business opportunities in the United Kingdom. Visits classified as miscellaneous have been having highs and lows generally below the 0% mark.
In conclusion, secondary sources of data are very useful sources of data. This is because; they save time, fast, and readily available, less costly and can be used for comparison purposes. If the data is used carefully putting into consideration factors of inaccuracy and distortion of the data.
Reference List
Baines, P., 2002. Introducing Marketing Research. New Yolk, NY: John Wiley & Sons. Web.
Balakrishnan, S., 1997. Do Important Restraint Policies Influence Marketing, R&D, and Manufacturing Orientations? Advances in Competitiveness Research, Vol. 5. Web.
Fletcher, H., 2001. Inside Information: Making sense of Marketing Data. New Yolk, NY: John Wiley & Sons. Web.
Gil, L., 1978 Design and Analysis of Experiments in the Animal and Medical Sciences. Iowa: Iowa State University Press. Web.
Grossnickle, J., 2001. Handbook of Online Marketing. London: McGrawHill. Web.
Hackley, C., 2003. Doing Research Projects in Marketing, Management and Consumer Research. New Yolk,NY: Routledge. Web.
Hofferth, L., 2005. Secondary Data Analysis in Family Research, Journal of Marriage and Family. Volume: Vol. 67. Issue: 4. Web.
Johnson, R., 2009. Statistics: Principals and Methods. Beijing: Laserwords Private Limited. Web.
Patzer, L., 1995. Using Secondary Data in Marketing Research: United States and Worldwide. Westport, CT: Quorum Books. Web.
Stiefel, L., 1990. Statistical Analysis for Public and Nonprofit Managers. New York, NY: Praeger Publishers. Web.
Urdan, T., 2001. Statistics in Plain English. Mahwah, NJ: Lawrence Erlbaum Associates. Web.
Walle, H., 2001. Qualitative Research in Intelligence and Marketing: The new Strategic Convergence Book. London: Quorum Books. Web.
Wrenn, B., et al., 2007. Marketing Research: Text and Cases. New York, NY: Best Business Books. Web.