The current paper discusses the concept of relational tables and dwells on the conceptual development of a database. The database deals with data on infectious diseases. The author of the paper specifies the unique names of the relational tables, attributes, and data characteristics. All the primary keys are identified and discussed. The author uses scholarly literature to approve the design choices made concerning the data input and data view.
The concept of relational tables
Relational databases are based on the concept of relational tables. This means that each of the tables consists of the fields (also called attributes) and lines of data that are termed records. There are several commandments that a relational database should comply with. First, there cannot be two identical records in a table. This postulate is based on a mathematical axiom presupposing relations within the table. Second, the attributes are added to the table in a certain order that is defined when creating a table. A table may not have a single record, but it is required to have at least one field (attribute). Third, each attribute should have a unique name, and all the values should be of the same data type (E.g., numeric, text, date, etc.).
The most important commandment is that there may be only one atomary value (not a group of values) on the junctions of each of the fields and records. The tables that satisfy the latter commandment are called normalized. One of the important notions connected to the concept of relational tables is the term “primary key.” The values of this attribute are required to be different in all the lines of the database (records). The selection of a primary key (PK) is a rather important task, and one should proceed with caution before choosing it. Another term that is connected to the PK is the foreign key (FK). It is usually utilized to show relations between the tables as each of the FK values correlates to a PK from another table.
Relational tables
The concept of the database includes five tables. The following representation comprises the table names and data types for each field.
Figure 1. Table “Nurse.”
Figure 2. Table “Patient.”
Figure 3. Table “Screening Result.”
Figure 4. Table “Screening.”
Figure 5. Table “Infection.”
Primary and secondary keys
The primary key for the table Nurse is the field Nurse_ID as it is an exclusive value for the reason that there cannot be two nurses with the same identification number. The foreign key for the table Nurse is the field Patient_ID as the relation between the nurse, and the patient is essential for the existence of the health care system. Another FK for this table is Screening_ID as it is also important to have the ability to display the screenings performed by a certain nurse. The primary key for the table Patient is the field SSN_Number as it is a unique value and will not be duplicated. The foreign keys are Patient_ID, Screening_ID, and Infection_ID. In this case, we will be able to receive an extensive array of the necessary data when organizing a query to the database. The tables Infection, Screening, and Screening_Result are auxiliary and serve as an asset to support the database and its normalized form.
Data input
The most reasonable decision, in this case, would be to use the data input that exploits the features of drop-down lists (Aksoy, Flores, & Monteiro, 2014). The use of drop-down lists would ultimately help the user navigate through the input process much faster than before. This may be explained by the fact that the notion of a drop-down list presupposes the division of the data into minor sub-categories (Samson & Nair, 2012). This would assist in saving the screen space and let nurses find exactly what they are looking for easily and comfortably. In general, the use of drop-down lists would be advantageous and offer a pleasing user experience (Meltzer, 2012).
Data view
The relevant data ( the result of the query) is going to be presented as a chart reflecting the number of successful screenings performed by a nurse (Fig. 5). This is a conceptual view of the output (Badia & Lemire, 2011). This data view proposal follows a simplistic design and presents only the information that is requested by the nurse at a certain moment. The following view shows the total number of screenings in selected patients and the percentage of screenings that identified the infection correctly.
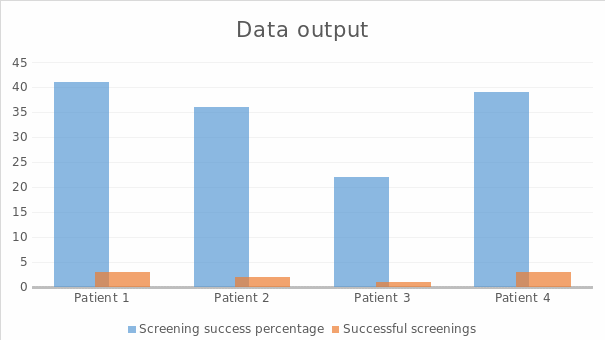
Conclusion
The output of this paper is a normalized database. This assignment is rather interesting and helps gain more insight into the conceptualization and developmental peculiarities of database planning. I understand the importance of the correct database design and will try to do my best when working on this assignment.
References
Aksoy, L., Flores, P., & Monteiro, J. (2014). Optimization of Design Complexity in Time-multiplexed Constant Multiplications. Design, Automation & Test in Europe Conference & Exhibition (DATE), 2014, 2(1), 1-62. Web.
Badia, A., & Lemire, D. (2011). A Call to Arms. ACM SIGMOD Record, 40(3), 61. Web.
Meltzer, B. (2012). Multimedia Database Systems: Design and Implementation Strategies. New York, NY: Springer.
Samson, R. H., & Nair, D. G. (2012). Computerized Registry for Endovascular Interventions. Handbook of Endovascular Interventions, 2012(1), 15-25. Web.