Introduction
The advancement in technology has heralded the onset of a whole new era in global networking. So much so that the safe keeping and continued existence of the discrete data has become an issue of global interest. Business institutions and well off individuals alike, are investing heavily in the security of their systems. They are buying sophisticated systems whose services may come in handy when there is need to operate their systems; be it in aviation, nuclear operations, and radiotherapy services or even in securing delicate information in sensitive databases. This creates a need for the service to be delivered. When the system can justifiably be trusted, it creates dependability.
Dependability entails the ability of computer systems to incorporate features that comprise its consistency, accessibility, data protection, its life and the cost of running and maintaining it. Failure of these systems leads to loss of delicate data and may expose the data to unwarranted parties. The main aim in this project is to highlight and expound on the primary ideas behind its operation.
After going through observations made over time in regard to their dependability on computer systems, people have tried to define dependability. From this in depth look at dependability then commences. It is rated according to the threats it faces, its attributes and how it ensures users of its dependability. Means of dependability are also looked into, by terms of how fast the system responds to queries, and the probability of generating results. Dependability merges all this tasks within a single frame work. Therefore the main purpose of this study is to present an on-point and brief outline of the model, the methodology and equipment that have evolved over time in the field of dependable computing.
The ideas behind dependability are founded on three basic parts that involve the threat to the system, the attributes of the system and the technique in play through which the systems achieves dependability.

Reliability
Reliability can be described in a number of ways:
It can be defined as, the idea that something is fit for a purpose with respect to time; the capacity of a device or system to perform as designed; the resistance to failure of a device or system; the ability of a device or system to perform a required function under stated conditions for a specified period of time; the probability that a functional unit will perform its required function for a specified interval under stated conditions or the ability of something to fair well (fail without catastrophic consequences) (Clyde & Moss, 2008).
In the dependability on computer systems, reliability architects rely a great deal on statistics, probability and the theory of reliability. A lot of business computer systems are employed in this type of engineering. They encompass “reliability forecast, Weibull analysis, thermal management, reliability testing and accelerated life testing” (Clyde & Moss, 2008). Since there is a big amount of reliability methods, their cost, and the changeable degrees required for diverse situations, a majority of projects build up a reliability-program-plan to identify the duties that will be carried out for that particular system.
The purpose of reliability in computer dependability is to come up with a reliability requirement for an item for consumption; establishment of a satisfactory reliability system, and performing of suitable analysis and tasks to make certain that end results meet necessary requirements. These particular tasks are controlled by a reliability manager, who is supposed to be a holder of an accredited reliability engineering degree. Additionally the manager has to have added reliability-specific edification and training. This kind of engineering is intimately linked with maintainability and logistics. Loads of problems emanating from other fields for example security can also be handled using this kind of engineering methods.
Availability
In dependability of computers, availability can be described as follows: the extent at which a system is, in a specific operable and committed state when starting a mission, “(often described as a mission capable rate). Mathematically, this is expressed as 1-minus unavailability; the ratio of (a) the total time a functional unit is capable of being used during a given interval, to (b) the length of the interval” (Blanchard, 2000).
An example for this is when “a component capable of being used 100 hours per week (168 hours) would have an availability of 100/168” (Blanchard, 2000).Though, distinctive availability values are shown in decimals i.e. 0.9998. In elevated availability functions, a metric, equivalent to the numeral of 9 that follows decimal points, is used. “In this kind of structure, 5 nines are equal to (0.99999) availability” (Blanchard, 2000).
Availability is well recognized in the writings of stochastic modeling and the finest maintenance. Barlow and Proschan (2001) for example describe availability of a fixable system as “the probability that the system is operating at a specified time”. On the other hand Blanchard (2000) defines it as “a measure of the degree of a system which is in the operable and committable state at the start of a mission when the mission is called for at an unknown random point in time.”
Availability actions are categorized by the time gap of interest or the devices for the systems downtime. “When the time gap of interest becomes the main concern, “we consider instantaneous, limiting, average, and limiting average availability. The second primary classification for availability is contingent on the various mechanisms for downtime such as the inherent availability, achieved availability, and operational availability”. (Blanchard, 2000)
Security
Computer dependability has a division known as computer security. This is a division of computer system technology dealing in information securities that are related to computers and networking. The purpose of computer-security includes the safeguarding of information from “theft, corruption, or natural disaster, while allowing the information and property to remain accessible and productive to its intended users” (Michael, 2005).
Computer-system security is the combined procedures and mechanisms by which responsive and important information and services are safeguarded from publication, interference or disintegration by illegal activities or unreliable individuals and unintended events correspondingly. The tactics and methodologies employed security-wise, often vary depending on the computer technology. This is because of its rather indefinable purpose of preventing unnecessary computer behavior, instead of allowing required computer behavior
Expertise on computer dependability security is founded upon logic. Because security is not essentially the most important goal of the majority of computer applications, planning a system with the issue of security in mind, frequently inflict restrictions on that program’s performance.
The following are four moves towards security in computers, sometimes a mixture of approaches come in handy:
Trust all the software to abide by a security policy but the software is not trustworthy (this is computer insecurity). Trust all the software to abide by a security policy and the software is validated as trustworthy (by tedious branch and path analysis for example). Trust no software but enforce a security policy with mechanisms that are not trustworthy (again this is computer insecurity). Trust no software but enforce a security policy with trustworthy hardware mechanisms (Michael, 2005).
Computers are made up of software performing on top of hardware. A computer system is a merge of these two components providing precise functionality, to comprise either a clearly stated or completely accepted along security policies.
Undoubtedly, quoting the Department of Defense Trusted Computer System Evaluation Criteria (TCSEC) archaic though that may be —the inclusion of specially designed hardware features, to include such approaches as tagged architectures and (particularly addresses stack smashing attacks of recent notoriety), constraint of carrying out text to the precise memory sections and/or register groups in computers and computer systems (Michael, 2005).
Safety
Safety is the condition of being safeguarded against “physical, social, spiritual, financial, political, emotional, occupational, psychological, educational or other types or consequences of failure, damage, error, accidents, harm or any other event which could be considered non-desirable” (Wilsons, 2000). This can also be described as the control of identified risks to attain a satisfactory level of risk. It can possibly take the structure of being guarded from the occurrence or from disclosure to something that brings about health or cost-effective losses. This can comprise the safeguarding of people or property.
Computer system safety or reliability is an engineering regulation. Continuous modification in computer knowledge, environmental regulation and community safety concerns make the scrutiny of compound safety critical structures even more demanding.
A common myth, for example in the midst of computer system engineers concerning structure control systems, is that, the subject of safety can be enthusiastically deduced. As a matter of fact, safety concerns have been exposed one after another, by many practitioners who cannot be assumed by one person over a small period of time. Information on literature, the standards and routine in any given field is an important part of the safety engineering in computer systems.
A mixture of theory and track-record of performance is involved and track-record points out a number of theory areas that are pertinent. In the US for example, “persons with a state license in professional systems engineering are expected to be competent in this regard, the foregoing notwithstanding, but most engineers have no need of the license for their work” (Bowen, 2003).
Safety is frequently viewed as a small part in a collection of associated disciplines these are: “quality, reliability, availability, maintainability and safety. (Availability is sometimes not mentioned; on the principle that it is a simple function of reliability and maintainability)” (Wilsons, 2000). This subject tends to establish the worth of any work, and insufficiency in some of these areas. “This is considered to bring about a cost, beyond the cost of addressing the area in the first place” (Wilsons, 200o); high-quality managing is then anticipated to reduce total costs.
Per-formability
Per-formability, at an initial impression, comes out like a simple gauge of performance. One may define it simply as an ability to execute a task or perform. In real sense, performance only constitutes about half any per-formability evaluation. This is actually a compound measure of a system’s dependability on overall performance. The measure is one of the fundamental assessment methods for degradable systems (extremely dependable structure s that can go through a refined degradation in performance when malfunctions are detected and still allows continuous usual operation). A good example of such a system that can be degradable is a spaceships control system having 3 central processing units (CPUs).
A malfunction in the system could be disastrous, perhaps even causing the loss of life. “Thus, the system is designed to degrade upon failure of CPU “1”, i.e. CPUs “2” and “3” will drop their lower priority work in order to complete high priority work that the failed CPU would have done” (Carter, 2009). The majority of functions in per-formability currently deal with degradable computer systems like the one mentioned. On the other hand, the idea is applicable to degradable structures in a diverse area starting from economics to biology.
Performance can be considered as the QOS (quality of service) as long as the structure/system is exact. Performance modeling on the other hand entails representations of the probabilistic nature of consumer demands and predicts the system’s performance ability. This is done under the supposition that the system-structure remains steady. Dependability is an “all-encompassing definition for reliability, availability, safety and security.
Thus it is what allows reliance to be justifiably placed on the service the system delivers. Dependability modeling deals with the representation of changes in the structure of the system being modeled”. (Ireson, 2006) These are usually due to errors, and how these changes influence the ease of use of the system. Per-formability modeling, then, considers the result of system changes and the effect on the general performance of the whole structure
At one time, the majority of modeling work separated performance and dependability. At first, dependability of structures might have been satisfactory, and then the execution was optimized. This brought about systems with good performance especially when they were fully functional, but a severe decline in executing tasks when, unavoidably, malfunction occurred. Fundamentally, “the system was either ‘on’ and running perfectly or ‘off’ when it crashed. Improvements on this, lead to the design of degradable systems”. (Lardner, 2002) Since degradable structures are designed to carry on with operations even after some component have failed (albeit at decreased levels performance), their ability to execute tasks cannot be precisely assessed without considering the impact of structural/system changes, breakdown & repair.
Initially scrutiny of the structures from a pure performance point of view was most likely optimistic because it disregarded the failure-repair performance of the systems. On the other hand, dependability scrutiny tended to be conservative; this is because performance considerations were not well thought-out. Therefore, it was fundamental that processes for the joint assessment of performance and dependability be increased.
Maintainability
“This is the measure of an equipment or systems ease and rapidness to restore its initial operational status as a result of a failure” (Randell, 2001). As shown by Randell again this “characterizes an equipment design to installation, availability of skilled personnel, and environment under which physical maintenance should be performed and how adequate the procedure of maintenance performs”. Maintainability is articulated as the likelihood that an item is retained in or otherwise reinstated to that definite condition over a said instance, when maintainability is being carried out accordingly to the set method and resources.
Maintainability merit is normally the MTTR (Mean Time to Repair) and a perimeter for the maximum repair time. Often it is expressed as; M(t) = 1-exp(-t/MTTR) = 1 – exp(-mt). M = constant maintenance rate, MTTR – Mean time To Repair (Laprie, 2005).
MTTR is a mathematical average implying a system repair speed and visualization is easier than the probable value. Maintainability concern is to accomplish shorter repair times for maintaining high availability so as to minimize cost control of downtime productive equipment at the time availability is critical. A 90% possibility that in less than or up to 8 hours, maintenance repair will have been completed with 24 hours as the maximum repair time could be a good maintainability goal.
Evaluation of dependability
Computing systems operate on five basic properties. These are: Functionality, usability, performance, their cost (both purchasing cost and operational cost) and their dependability. The ability of a computer system to deliver the appropriate service and gain the trust of an end-user is referred to as dependability. Service delivery refers to the efficiency of the system as per the view of the user. The function of the system refers to its intended use, as is prescribed by a particular system’s specification. When the system carries out the intended service it was meant for without a hitch, and delivering on time, it’s referred to as correct service.
When the system fails to deliver a service it was made for, or shows some deviation from rendering the correct service it’s referred to as system failure. This is also called an outage. When this happens and the system is restored to performing its original service, it is called service restoration. Reflecting on the understanding of the definition of system failure, dependability can be defined as “the ability of a system to avoid failures that are more frequent or more severe, and outage durations that are longer, than is acceptable to the user(s)”(Jones, 2000).
System failure may be associated with its non-complicity to a given specification or if a program’s function is not fully described. This part of a system that may in future cause system breakdown is called an Error. The assumed cause of an error is referred to as a Fault. When a fault in a system produces leads to an error, then the fault is active, if it is in an inactive state then it is dormant. There are various ways through which a system can fail. The failure modes can be ranked according to how severe their exposure to the system can be. The positions, with which they are categorized, are classified into three categories. These are; “the failure domain, the perception of a failure by the end-user and the consequences of these failures to the environment” (Laprie, 2005).
An interactive set of components forms a system set while component states encompass the system state. When there is an error it causes a malfunction in the state of the components but it will not lead to system failure unless it encroaches up to the service interface of the system. One of the ways used to classify errors is categorizing them according to the component failure they cause.
A system comprises of a set of interrelating components; consequently a system state is a set of its constituent’s states. A fault initially causes inaccuracy inside the state of a component, but the whole structures malfunction will not come about as long as the fault does not get to the service interface of the whole structure. A suitable categorization of errors is described in terms of component malfunction that they bring about.
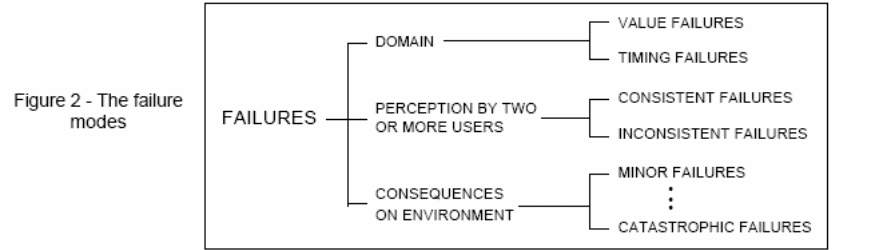
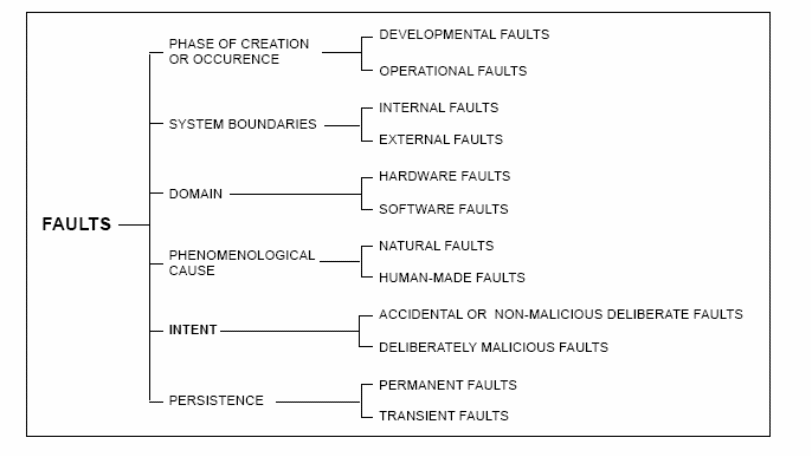
Using the expressions in the figure above, “value vs. timing errors; consistent vs. inconsistent (‘Byzantine’) errors when the output goes to two or more components; errors of different severities: minor vs. ordinary vs. catastrophic errors” (Schneider, 2000). A mistake is noticed if its existence in the particular system is specified by an error note or signal. Errors/faults that are in the system but not identified are dormant errors. Faults and their causes are very varied. Their categorization as per the 6 chief criteria is shown in Figure 3 below.
It could be argued that introducing phenomenological causes in the classification criteria of faults may lead recursively to questions such as ‘why do programmers make mistakes?’, ‘why do integrated circuits fail?’ Fault is a concept that serves to stop recursion. Hence the definition given: adjudged or hypothesized cause of an error. This cause may vary depending upon the viewpoint that is chosen: fault tolerance mechanisms, maintenance engineer, repair shop, developer, semiconductor physicist, etc (Schneider, 2000).
Elementary fault classes
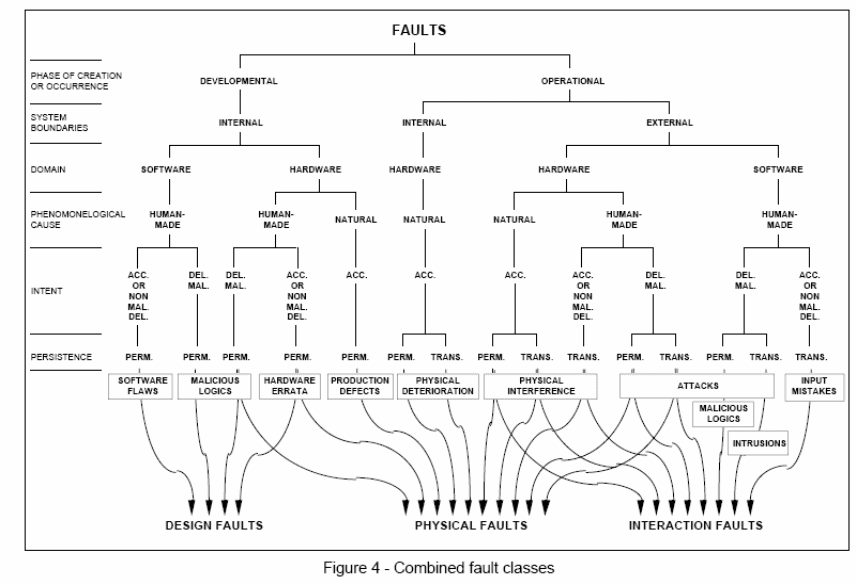
Conclusion
The main concept of dependability is its nature to incorporate which in turn “permits the putting on board classical notions of “reliability, availability, safety, security, maintainability, that are then seen as attributes of dependability.
The fault-error-failure model is central to the understanding and mastering of the various threats that may affect a system” (Newman, 2003). This facilitates unified presentations of the threats, at the same time preserves their specificities through a range of fault classes which can be definite. Another important aspect is the employment of a fully generalized idea of failure as is contrary to one which is limited in some way to scrupulous types, reasons or outcomes of failure. The model presented as a way for achieving dependability is exceptionally valuable. It is because the means conforms to the attributes of dependability. This is again with regards to the design of whichever system has to carry out trade-offs owing to the fact that the attributes are inclined to clash with each other.
Computers and digital devices are increasingly being used in significant applications where failure can bring about huge economic impacts. There has been a lot of research and presentations describing techniques of attaining required high dependability. To achieve the desired dependability, computer systems are required to be safe, secure, readily available, well maintained, and reliable, have enhanced performance and robust against a variety of faults that includes malicious mistakes from information attacks. “In the current culture of high tech tightly-coupled systems which encompass much of the nationalized critical communications, computer malfunction, can be catastrophic to a nation’s, organization’s or individual’s economic and safety interests” (Mellon, 2005).
“Understanding how and why computers fail, as well as what can be done to prevent or tolerate failure, is the main thrust to achieving required dependability. These failures includes malfunction due to human operation, as well as design errors” (Mellon, 2005). The aftermath is usually massive, as it embodies record loss, lack of reliability, privacy, “life loss, or even income loss exceeding thousands of dollars in a minute” (Mellon, 2005). By system structures that are more dependable, such effects can be avoided.
References
Algirdas, A. (2000). Fundamental concepts of computer systems dependability. Los Angeles: Magnus university press.
Barlow, A and Proschan, N. (2001). Availability of fixable systems. Computer systems, 43, (7): 172-184.
Blanchard, D. (2000). Availability of computer systems. New York, NY: McGraw-hill.
Bowen, S. (2003). Computer safety. IBM Systems journal, 36 (2): 284-300.
Carter, W. (2009). Dependability on computer systems. Computer systems, 12 (1): 76-85.
Clyde, F., & Moss, Y. (2008) Reliability Engineering and Management. London: Mc-Graw-hill.
Ireson, W. (2006). Reliability engineering and management. London: McGraw-hill.
Jones, A. (2000).The challenge of building survivable information-intensive systems. IEEE Computer, 33 (8):39-43
Laprie, J. (2005). System Failures. International journal of computer technology, 92 (3): 343-346.
Lardner, D. (2002). Degradable computer systems. P. Morrison and sons Ltd.
Mellon, C. (2005). Dependable systems. London: McGraw Hill
Michael, R. (2005). Computer software and hardware security. New York, NY: CRC Press.
Newman, B. (2003). Fault error failure model. Sweden: Chalmers university press.
Randell, B. (2001). Computing science. UK: Newcastle University press.
Schneider, F. (2000). Faults in computer systems. National academy press.
Wilsons, T. (2000). Safety. London: Collins & associates.