Server Availability Enhancement
The server execution environment may experience failures due to memory errors caused by memory corruption. Such failures are typically caused by programs attempting to make invalid point access and out-of-bounds array accesses. While this situation can be corrected using programming languages such as Java and ML, these errors can be addressed by enabling programs to execute based on a failure-oblivious computing technique (Rinard, Cadar Dumitran, Roy, Leu & Beebee, 5). The technique allows a program to continue executing in an error-prone environment without throwing exceptions when errors are encountered by running programs. That reduces server vulnerability to security attacks due to memory errors.
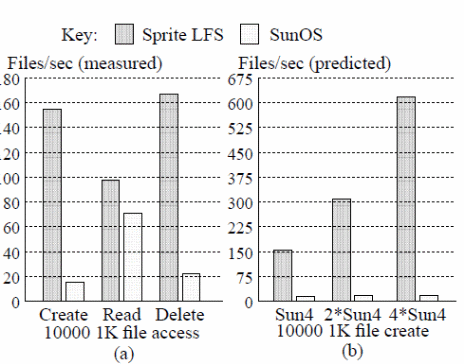
A typical C compiler environment test results have shown the technique to be an error-free execution and reliable environment in view of the above errors in a server environment. The failure-oblivious computing technique allows a server to concentrate on executing critical data and discard any errors detected in the program execution environment. During program execution, minimal error propagation lengths and error flow characterize the technique. In theory and practice, the technique has been proven to be secure and of low cost with minimal overheads in server administration (Rinard, Cadar Dumitran, Roy, Leu & Beebee, 10). On the other hand, critical disadvantages with the failure-oblivious computing technique include execution path failures, bystander effects that are generated during program execution, and limited user experience. The technique can be implemented using two sets of codes as has been demonstrated with the Apache server when appropriately configured. Other operating environments with similar experience include sending mail on the Linux operating system, midnight command which is an open-source software environment, and Mutt which is configured for the Unix environment as a text-based mail. All these are critical to ensuring user data and memory remains secure and aptly managed based on new file management systems (Rinard, Cadar Dumitran, Roy, Leu & Beebee, 14).
Log-Structured File System
A log-structured file system is a new approach to disk storage management where files are assumed to be cached in a memory that is dynamically expanded in a sequential log structure. The approach improves the write operations while maintaining system integrity during crashes. To enhance the efficiency of the log-structured file system, a segment cleaner dynamically creates free space based on different technological designs (Rosenblum &. Ousterhout, 5).
Technology-driven file system improvements have focused on dynamically improving disk storage technology, system design and organization, CPU architecture, and main memory speeds. The development was basically meant to address identifiable problems with the current technologies. These problems include limited data access due to file attributes and synchronous file writing mechanisms. However, the log-structured file system provides an improved fashion of write performance through a sequential write mechanism after data buffering has been done such as is practical in a Unix environment. One of the techniques for improving performance includes segment cleaning as illustrated in the fig. below (Rosenblum &. Ousterhout, 7).
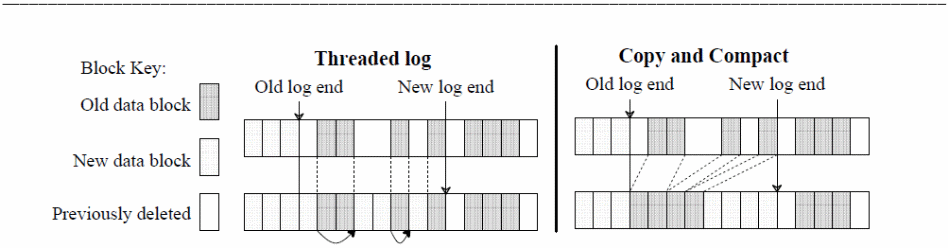
Segment cleaning is prioritized on the time to clean, space to clean, segments for cleaning, and blocks grouping policies as illustrated below.
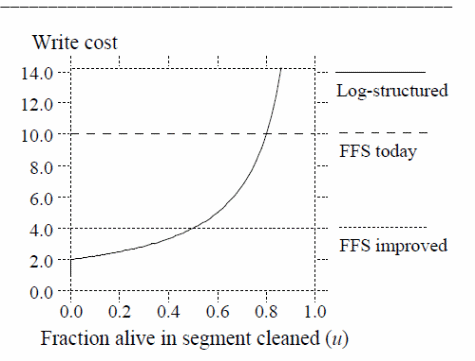
Performance-based evaluation of the system can be calculated based on the write cost mathematically related below (Rosenblum &. Ousterhout, 6).

The memory size cleaned for different types of files is illustrated below.
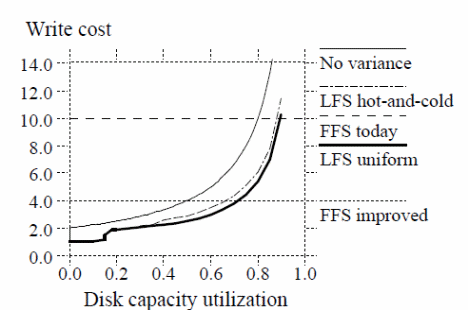
On the other hand, simulations done on the effects of different cleaning policies are summarized in the graph below (Rosenblum &. Ousterhout, 12).
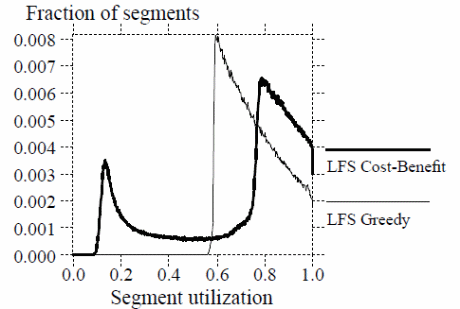
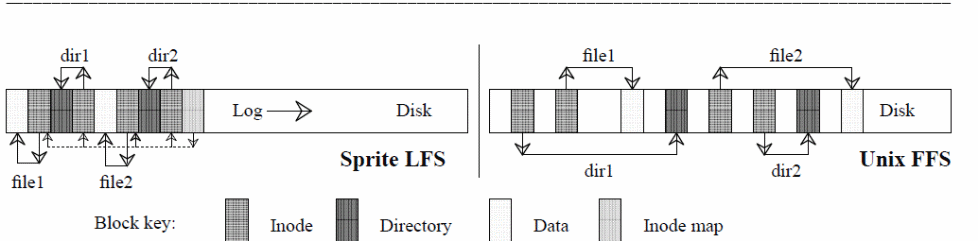
Other strengths of log-structured file systems include the ease with which log points can be traced due to crashes, dynamic checking of log points, the ability to incorporate a roll-forward recovery mechanism, and the establishment of checkpoints. Typical of that system are SunOS and Sprite LFS as illustrated below (Rosenblum &. Ousterhout, 14).
Rethink the Sync
To exploit the full benefits of new developments in input/output management and improved performance, a fast synchronous input provides high reliability, durability, better ordering, and efficient programming. It provides a user guarantee without an intermediation of an application since the possibility of blocking applications impedes program performance. A typical example of impediment to system performance is a blocked application shown below (Nightingale Veeraraghavan Chen & Flinn, 10).
- write (buf, 1);
- write (buf, 2);
- print (:work done”);
- foo ();
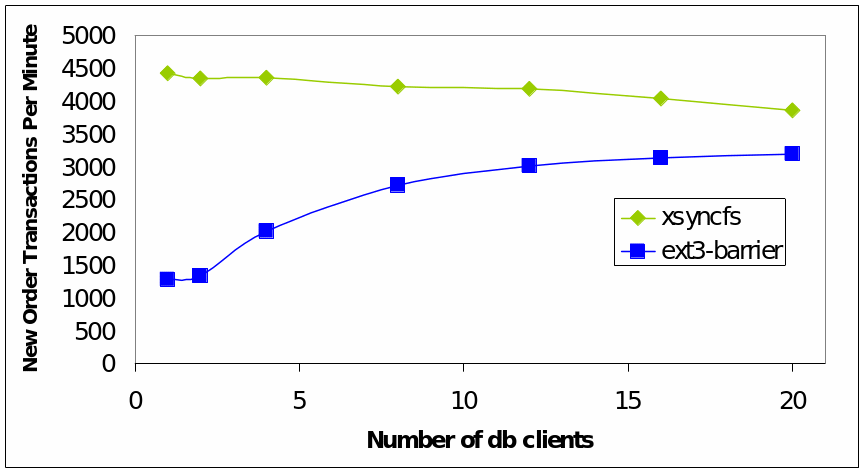
Performance enhancement can be achieved by ordering an application to achieve synch I/O. It is possible to trace casual dependencies to evaluate the performance and security of a computing system. Typically, that is where programs share data and communicate through sockets, pipes, etc. Typical approaches to tracing these dependencies include IPCs and SOSP’5. A typical example of a commit a single commit environment is illustrated below (Nightingale Veeraraghavan Chen & Flinn, 19).
In conclusion, therefore, sync I/O is performs faster compared with async I/O operations (Nightingale Veeraraghavan Chen & Flinn, 13).
Rleceivelivelock
Interrupt driven operating system network task scheduling suffers from performance overheads and low latency at low load and poor performance at higher input rate. Livelock problems leading to underperformance are specific to applications such as host-based routing which includes internet firewalls typical of the Windows XP and Unix operating systems (Mogul & Ramakrishnan, 16). Network file services demand system throughput, stability, uniform resource allocation, and reduced latency and jitter (Mogul & Ramakrishnan, 25).
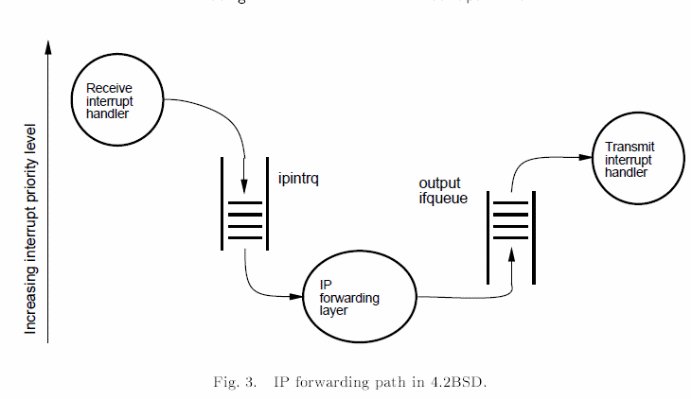
The interrupt driven approach suffers from receive livelocks, and starvation of packets being transmitted. It is important to note that a typical cause of latency is illustrated below.

However, typical strategies of overcoming scheduling problems include ensuring the rate at which interrupts arrive is reduced to the minimal, incorporating the use of a polling strategy, and keeping the operating environment free of preemption. A typical application includes a BSD router as summarized in the fig. 1 below (Mogul & Ramakrishnan, 13).
However, the livelocks problem can be fixed by modifying the flow on the kernel as illustrated below.
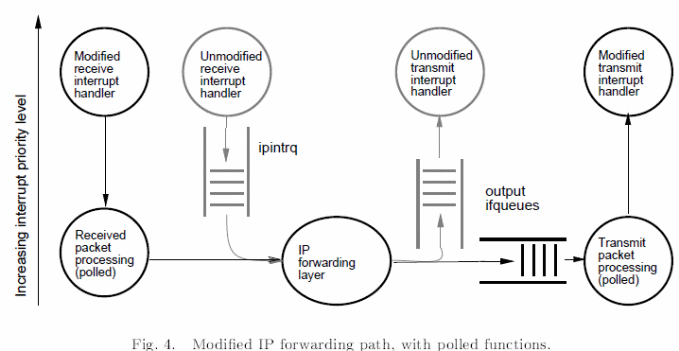
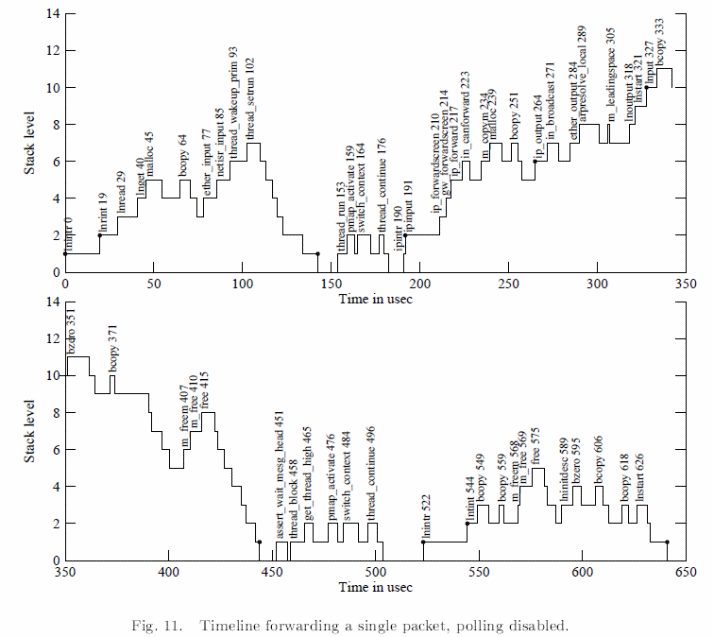
In theory, scheduling heuristics can be achieved on data from full queues and the number of packets and quotas which include the number of packets screened per unit call back. User level progress can however be achieved through TCP threading at lower levels and CPU cycle limitations. However, these achievements can be practically achieved by tracing kernel packet executions and packet activities as illustrated below. In addition, it is also possible to avoid such livelocks in a promiscuous monitor using stamps for write operations (Mogul & Ramakrishnan, 24).
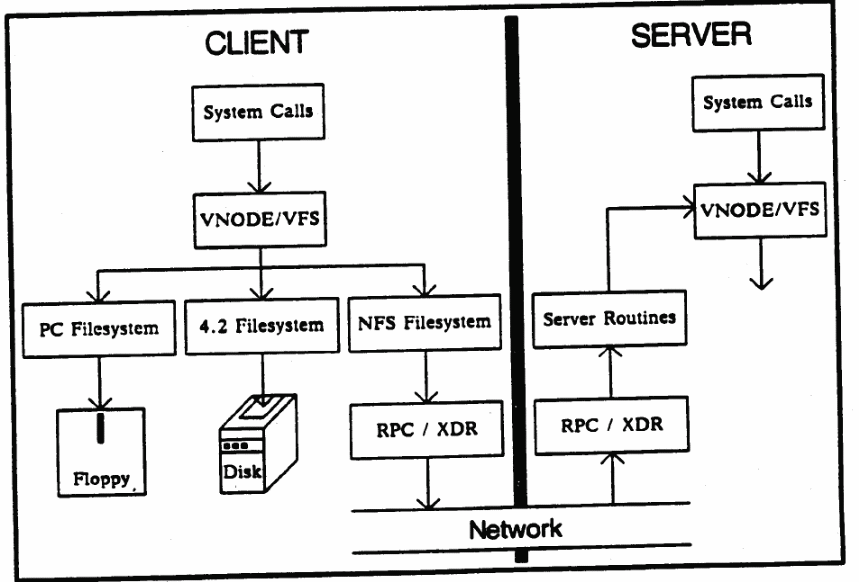
Sun Network File System
One distinguishing benefit of the sun file system is that it allows transparent file access which may be remotely located. The file system is portable and accommodates different operating systems architectures (Sandberg, Goldberg Kleiman, Walsh & Lyon, 7). Typically, to design a NFS, and achieve efficient sharing of files, the design has to meet design goals which include the independence of the OS and the machine, easy recovery of the cache, among others. The basic structure of the NFS is composed of the server and client sides and the working protocol. The basic design and operation is illustrated below.
Efficient Fault-Tolerant and File Cache
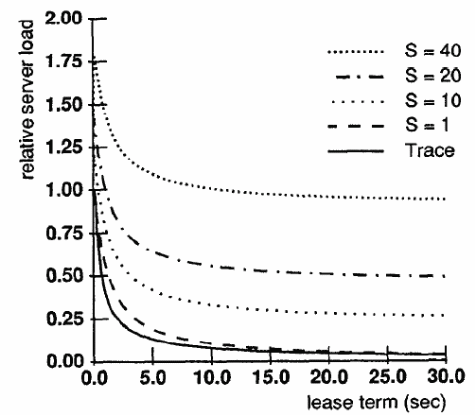
To ensure performance benefits of the cache memory are optimized, consistency overheads problems for cached primary data can be addressed appropriately using consistency protocols, short term, and long term leases (Gray & Cheriton, 3). Lease terms can be addressed based on the relation, typical of server processing time as:
The relative performance of the system and the lease term are expressed in the relation illustrated graphically below (Gray & Cheriton, 7). However, other leasing options depend on the server without need for a write approval. Typical leasing benefits include fault tolerance among others (Gray & Cheriton, 9).
File System
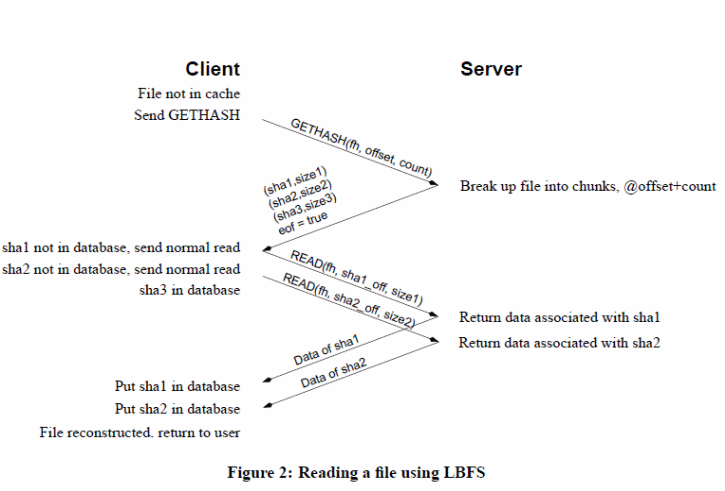
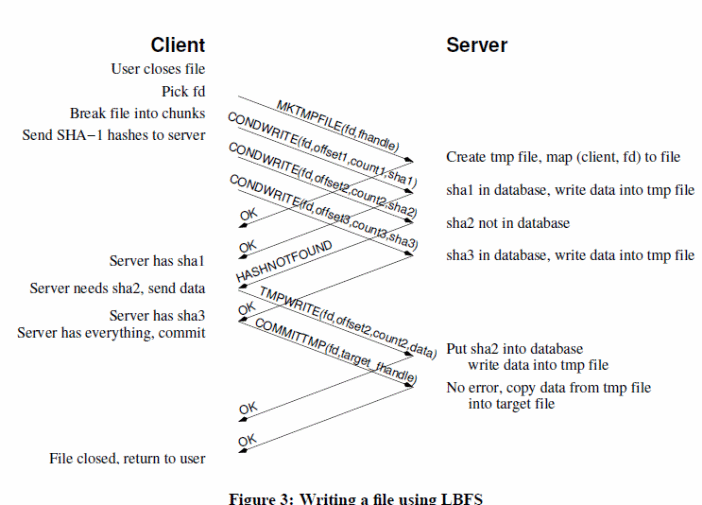
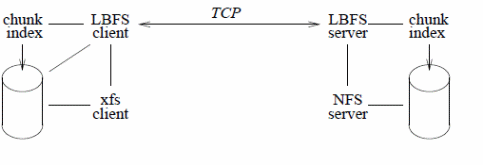
To enhance file access performance on remote locations, different LBNFS have been designed to address the issue. LBNFS uses appropriate algorithms and protocols to address the bandwidth problem (Muthitacharoen Chen & Mazi eres, 2). LBNFS optimizes bandwidth, indexing, use of chunk files, databases with a 64 bit index, file caching based on the three-tier scheme to perform file reads and writes operations, server and client implementations with a normalized end to end enhanced performance illustrated below ( Muthitacharoen Chen & Mazi eres, 13).
Energy Management and Concurrency Control
In the modern server operating environments, energy conservation is a critical component to factor when designing and implementing device driver architecture that addresses the energy problem. A typical benefit derived from minimal power consumption is improved system life and performance. One typical approach is operating systems to manage energy consumption where applications and peripheral devices use energy appropriately (Klues, Handziski, Lu, Wolisz, Culler, Gay, & Levis,3). That is typical of the three concurrency classes used by ICEM drivers with different views such as dedicated single users and appropriated device driver management as illustrated below (Klues, Handziski, Lu, Wolisz, Culler, Gay, & Levis, 3).
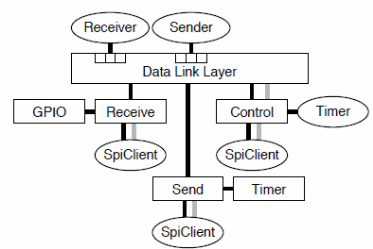
The system uses split phase power locks, component power libraries, and sleep management strategies typical of the Telos energy and code complexities.
Simplified Data Processing
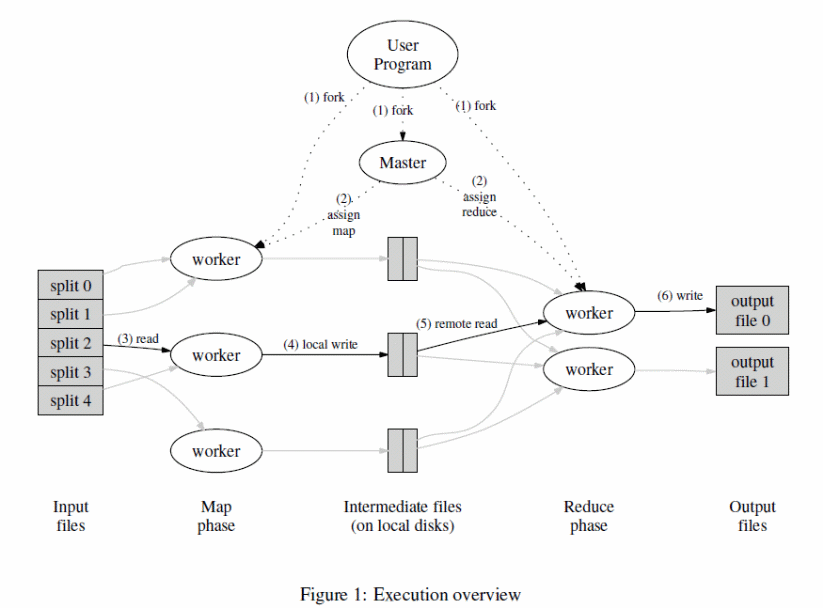
One of the modern approaches and techniques to effectively and efficiently process large sets of data is based on the MapReduce technique. Typically, the technique allows for large and powerful computations on large clusters. These computations can be achieved based on programming models on an execution mechanism indicated below (Dean & Ghemawat, 5).
The MapReduce function is one of the critical program execution components that correspond with fragmentation of input files, use of a copy of a special program, reads of input splits, partitioning and writing the local disk, and use of a RPC to enable communication between data holding locations (Valiant, 5). Practical environments that have incorporated MapReduce are Google and able to scale further with an additional characteristic to make the model fault tolerant. The model optimizes data communicated through a network based on the locality optimization technique and enhances performance on small machines (Dean & Ghemawat, 3).
Klee
To achieve performance levels specific to an intensive program execution environment, KLEE is a tool tailored to meet the intensive data requirements for the environment. Typically, KLEE optimizes higher data concentrations on altered applications by identifying inherent errors in intensively tested code (Cadar, Dunbar, & Engler, 2). In addition to that, KLEE automatically finds functional correctness errors based on BUSYBOX as one of the tools. KLEE provides a flexible environment for checking errors by running KLEE bytecodes. Architecturally, KLEE is defined by an interpreter loop which executes identified and selected code. Data storage within the KLEE environment is based on trees typically defined by symbolic vales and constants typically stored in a concrete storage location with constant expressions. The greater amount of data executions are based on symbolic executions (Cadar, Dunbar, & Engler, 3).
Architecturally, KLEE is a hybrid between the operating system and an interpreter from the perspective of symbolic processes which are defined by heaps, program counters, typically indentified as states in other environments. In the program execution environment, Boolean expressions are evaluated for correctness by the KLEE problem solver mechanism to direct the instruction pointer at the appropriate location in following the correct execution path. Typically efficient system performance is partly achieved by the characteristic component of KLEE that allows it to track every memory object during program execution. In addition to that, the technique allows query optimizations for expression rewriting, constraining implied values, and ensuring values are typically constrained independently. To optimally achieve system success, KLEE uses random path selection strategies with variations in instruction executions based on different time slices. The technique allows for file modeling mechanisms in a real operating environment to achieve optimality of system performance. A typical test data approach and results are illustrated below (Cadar, Dunbar, & Engler, 9).
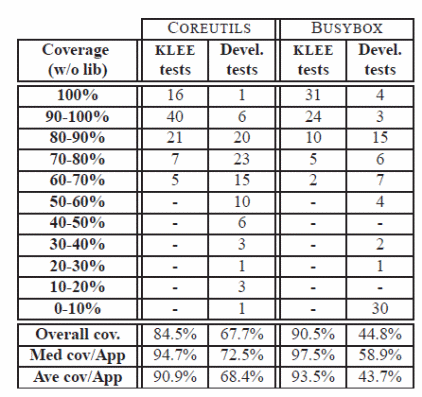
Arguably, test results for above techniques indicate different levels of correctness error typical and uniquely identifiable with each application. Further observations indicate that KLEE to typically identify and remove problems in a networking environment using typically tailored tools. Among the functional advantages with KLEE is its degree of accuracy and constraint solver strategies. In addition to that, the technique can be applied on a broad spectrum of applications with a high success rate and precision (Cadar, Dunbar, & Engler, 15).
Works Cited
Cadar, Cristian, Dunbar, Daniel, & Engler, Dawson. KLEE: Unassisted and Automatic Generation of High-Coverage Tests for Complex Systems Programs. Stanford University. n.d.
Dean Jeffrey & Ghemawat, Sanjay MapReduce: Simplified Data Processing on Large Clusters. Symposium. 2004.
Gray Cary G. & Cheriton, David R. Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency. Stanford University. n,d.
Klues Kevin, Handziski Vlado, Lu_ Chenyang, Wolisz, Adam, Culler David, Gay David & Levis, Philip. Integrating Concurrency Control and Energy Management in Device Driver. n.d.
Mogul C., Jeffrey & Ramakrishnan, K.K. JKElFeiFmrRnEienYlaCt.iMnOgGURLeceiveLivelockinanInterrupt-Driven, AT & T Laboratory Research. 1997.
Muthitacharoen Athicha, Chen Benjie & Mazi eres, David. A Low-bandwidth Network File System.
Nightingale Ed, Veeraraghavan Kaushik, Chen Peter, Flinn Jason. Rethink the Sync. University of Michigan, Lecture notes.
Rinard Martin, Cadar Cristia, Dumitran Daniel, Roy Daniel M., Leu, Tudor & Beebee, William S. Enhancing Server Availability and Security through Failure-Oblivious Computing. Massachusetts Institute of Technology. n.d.
Rosenblum Mendel &. Ousterhout John K. The Design and Implementation of a Log-Structured File System. Berkeley, CA. 1991.
Sandberg Russel, Goldberg David, Kleiman Steve, Walsh Dan & Lyon Bob. Design and Implementation of the Sun Network File system. Mountain view, CA. n.d.
Valiant. L. G. A bridging model for parallel computation. Communications of the ACM, 33(8):103–111, 1997.