Introduction
This introduction involves different works of research on different topics as in the whole paper dealing with systems, databases, programs, and web services. With the introduction of world-wide-web, a dissimilar change is being felt to the use of files as a corporate basis of data. Apart from proprietary designs, a lot of businesses are utilizing the web for the reason of their data formation, storage, and circulation requirements.XML introduction with, advanced control over the meta-data and document structure has evidently improved the likelihood of document organization on the web. Most relational database SQL (structured query language) is the language that is mostly accepted [SQL 86, SQL89, SQL92].
It is being popularly known as object Oriented or query language or object Relational (OR) database (Astrahan& Chamberlin, 1975, p. 1). It’s used as a Data manipulation language (DML) also data definition language and data (DDL) query language (DQL). Achieving the broad case-based reasoning prop up for corporate reminiscences will need elasticity in transforming implementations with presented organizations resources and infrastructures(Bancilhon &Delobel, 1992, p. 2). Ontology web language services (OWL-S) are the many efforts being used to enable ontology development “for semantic web services”.
When unfolding web services, one of the noticeable aspects that desires represented is Quality of Service (QoS), the potential of web service to convene satisfactory point of services as for each factors such suitability, accessibility, performance, truth and reliability compliance security, and regulatory XML is one of the widely used data version and data swap formats. The figure of XML connected developed and under development applications is significant. A lot of research on XML has focused on developing resourceful mechanisms to accumulate and handle XML data either as an element of a relational database or using indigenous XML stores.
Though, hiding secured data is important. You can copy a section of these materials without paying the fee as long as you don’t use copies and supply for straight commercial benefit. Copying permission is given by Very large Data Base Endowment (VLDB) copyright notice, publication title and its data appear. To republish you pay a fee or special agreement from the Endowment. This paper is about five units namely: move from SGML database and bring SQL, transforming of case-based reasoning, access control for XML-A dynamic Query rewriting approach, web services Ontologies for QOS and general quality evaluations and transitioning existing content: inferring organization-specific document structure. This research paper mainly deals with systems, web services and majorly how to handle databases (Elmasri &Shamkant, 1989, p. 3).
SQL-Standard
SQL original standards date back 1986[SQL 86] the language is still developing the advances in the hypothesis in databases and practice. The original SQL 86 was improved thus the introduction of the version SQL 89. Standard [SQL92, MS92] which also referred to as [SQL2] which was improved from the standard [SQL89] was published to due non-limitations in programming (Melton & Simon, 1992, p. 4). With the introduction of Object-Relational and Object-oriented technologies users of SQL may see the transformation to [SQL96] which is in the extension. This paper mainly focuses on the latest version which is SQL2 (Sengupta & Dillon, 1996, p. 5).
Relational Databases
SQL was intended to work through relational databases. flat tables is the form Data is stored, in which tuples or rows denotes one record of the data, property of data is represented by fields or columns in technical terms also called as Meta-data which is an explanation of data. E.g. “BookName” in the field is the data in the table while SGML Handbook, data is “SGML Handbook” therefore meta-data is Book name. SQL principle has a direct correspondence to Generic Identifiers (GIs) in SGML are the meta-data and data in the GIs are the character content. Meta-data in relational databases have more associated information such as data size, data type, and index type. Flat structure in relational databases is one of the problem. In a relational database composite hierarchical structure need to be mapped to corresponding the flat structure (Melton & Simon, 1992, p.5). Entity-relational (ER) is the most used model of data to conceptually represent a relational database. Objects such as name, book city, are referred to as entities (Sengupta & Dillon, 1996, p. 6).
SQL- A Brief Introduction
SQL came from SEQUEL (structured English Query Language) the original version which was developed by San Jose IBM’s research laboratory. The proposed SQL3 [SQL96] has completely turned SQL into a programming language i.e. Object-oriented. Not only SQL is restricted to Queries for being known as a Query language, but it also deals with: (DQL) data query language, (DML) data manipulation language, and (DDL) data definition language (Sengupta & Dillon, 1996, p. 7).
DDL properties
This mainly deals with the structures of data in the Database; in SQL you can also call meta-data. The database is the highest level in SQL structure which contains indices, tables, and views. Structures can be deleted and created using DDL statements DROP AND CREATE. E.g. CREATE TABLE CARS (MAKE CHARACTER (15) NOT NULL, REG NO INTEGER). The statement above creates a table called cars with make and reg no. some statements used are, ALTER TABLE, DROP TABLE, AND DROP DATABASE.
DQL- Properties
Mainly focuses on querying data by formulating SQL Query statements. SELECT is the most commonly used SQL statement. SELECT describes what you want with condition FROM.
Querying From the SGML and Suggested Extensions to SQL for Use with SGML
Schema representation distinguishes SGML from relational databases. In SGML query can be defined easily by not using complex statements like in the SQL. Complex structures in SGML are easily represented since you do not require documents breaking into cuts to stand for them while SQL can not deal easily with complex structures. Main extensions required to use SQL with SGML documents initiate the steering of the tree structure, and use other objects to make complex objects. Three primarily proposed extensions in previous work [SD96] are the cascading of the dot (membership or “.”)Operator, using operator of double-dot ((“..”) children) and having the capacity to indicate a DTD form in the SELECT clause to divide and make complex types (Sengupta & Dillon, 1996, p. 7).
Theoretically, these extensions are not complete, core SQL can still demonstrate with a few minor extensions that may enable enormous rules to the query language. In Object-Oriented languages, SQL has been adopted and used in Object-Oriented database 02 like the Reloop language. One problem SQL is not a nice query “full text” language when used in the relational domain. Even SQL con does not conduct schema-independent queries, with the proposed SQL extension eliminating this setbacks to an enormous point. However to be efficient SQL still requires data along with meta-data. With standard SQL, because of its relational database structure there is no need to navigate a hierarchy unlike in SGML where it is important to navigate (Sengupta & Dillon, 1996, p. 8).
Inferring Organization-Specific Document Structure
Automatic DTD Generation
DTD stands for document type definition, which can be extracted from the XML documents. Data Descriptors by Example [DDbE] [Diaz and Berman 1999] is a java library, alpha works from IBM can generate DTD fro XML document. You can generate DTDs from document using DTD GEN [Kay, 1999????] Software that is available freely that uses rules that are simple. Similar results can be gotten using XTRACT [Garofalikis et al, 2000] designed in the Bell labs which is the most recent software. Freed (Shafer, 1995, p. 8) well known tool which is dated can generate DTDs from random SGML documents (may be used in most of the XML documents). These tools are to generate DTDs which have been purposely validated for the suitable class document (Berman &Diaz, 1992, p. 2).
Database Reverse Engineering
A rich flow of research has focused on different reverse engineering shortcomings like reengineering of attributes, entities, ternary relationship and binary relationship. The main technological model attempt has been the data relational model. Innovative results and practical have been attained due to stream of researches. Reverse engineering document structures has key differences to the reverse engineering databases which cause a direct application of different results. Document contain unstructured data unlike it is in other relational databases (Berman &Diaz, 1992, p.2). This mainly focuses on the individual document not many. Due to underdeveloped XML schema standards it’s functionality to documents with extended links is poorly implemented compared to well established foundation in database schemas (Garofalakis &Gionis, 2000, p. 3). Reverse engineering considers some instances to identify with attributes and entities in conceptual and relational schema. While others (DDbE, XTRACT, FRED) which focus on XML solo instance document.
Inferring Document Structures
DTDs can be compiled directly from the XML document using a tool such as described above e.g. (FRED). It is fairly easy to generate DTDs from XML as opposed to the SGML, since well-formedness assures DTD be constantly inferred from the document. The importance of the research is to generate generic DTDs that will capture the information in a particular document instances, but solo document may involve rewriting to be validated with DTD (Goldfarb & Prescod, 2000, p.3).
Document Structure Generation Heuristics
A normative DTD to be generated consider a number of issues from probably inconsistent documents with the similar common structure. Definitive solution can be reached in some cases, where most cases need some experience and intelligence to choose resulting structure.
A Framework for Automated Construction and Transformation of a Case-Based Reasoning
CBR (case-Based reasoning) systems as presently constructed tend to fall into three common implementation models. Task-based implementations customarily have highlighted system goals concerning only the constraints forced by the reasoning task itself. The majority of research systems e.g. focus on certain (frequently idiosyncratic) representation and methods optimized to tackle specific reasoning task, either to display the success of the method or rally specific task goals( Purao &Storey, 2000, p. 4). Recently CBR has been a successful and an increasing of adopting into enterprise systems like (Wat97, SW98) to control corporate data assets by knowledge management e.g. [BFA99]. Enterprise executions act in response to the additional implementation restraints enforced on CBR systems as part of the normally enterprise architecture [KS96].in their views is that CBR integrations must operate in conjunction with database systems, basis of corporate knowledge doings which is the most vital implementation constraint in this perspective is that naturally(Allen &Patterson, 1995, p. 3).
Implementations in CBR make use and provide for the database functionality either in object database systems e.g. [EII95] or relational database systems (e.g. [GW98]). Not all implementations in CBR enterprise systems will make sense. CBR currently budding system that take benefit of new developments in knowledge sharing and editions of the world-wide web e.g. [GW98, Shi98, DFH+98]. Implementation based on the web reacts extra constraints forced on the CBR systems by compliant to structure documents depiction standards for network/web communication in particular Extensible Markup Language [XML] e.g. [BPS98]. The paper is based on coming up with a real reasoning system, not targeting how it presents data. Web implementation most probably might not have a web interface while on the other hand task-based implementation might have a web interface. So it is important to understand (1) how models compare (2) their combination (3) their individual construction and especially (4) and how one may be built by transforming another (Berchtold &Bohm, 1997, p. 6).
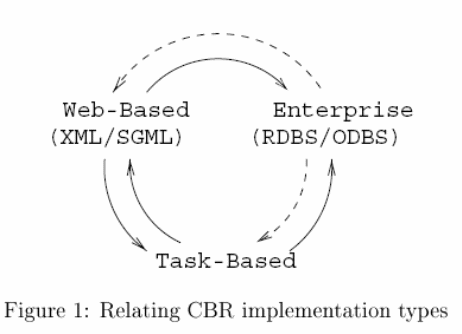
Implementation Models
Implementation characterizations are practical at many levels of typical CBR systems, here we protect it’s useful to separate CBR representation and process. This debate is single limited to a relational database and XML Task-Based molds by not concerning with Standard Generalized Markup Language (SGML) and multifaceted entity plus molds of Object-oriented. Enterprise: incorporating in Case-Based Reasoning realizations with enterprise database regularity restraints is enforced by the systems that are virtually common in the enterprise society. Representations must match up table representation or model of Relational Database Systems (RDBS) whilst process have to allow SQL conventions. RDBS’s underlying strength are gained by CBR systems, such as recovery/backup, security, scalability and concurrency control. Data representation on the web is using emerging web-based XML as the tool (Shafer, 1995, p. 5).
Realizing Implementations
This realization involves representation and outlining process for each model, as well as illustrating and defining transformations between models.
Enterprise/RDBS
Involve a case structure and a relational database being associated. CBR general systems can be represented using ER (Entity-Relational) model properly identifying the unlike component of the crisis space. If knearest neighbor (k-nn) retrievals is implemented CBR process can use database systems (Fernandez &Aha, 1999, p.9).
As a result Case-Based Reasoning/folder or database development is seen acting nearly on three stages;
- uncomplicated storage space: database is employed as medium of storage of data. Exterior or external systems are employed in to retrieve or extract and process cases. You can use SELECT*FROM case_table incase o query.
- Simple Retrieval: an easy selection done based on setting used from the target, and the outcome subset is externally processed. Query statements is, SELECT*FROM case-table WHERE conditions.
- Metric Retrieval: use metric function. Basic query is SELECT * FROM case table ORDER BY metric (k).
Access control fer xml- a dynamic query rewriting approach
Proceedings of the 31st VLDB Conference, Trondheim, Norway, 200
The data making is efficiently accessible, For example an XML tree document, and you may have unlike user groups with different access permissions to parts of the document. Model of security specification must ensure that these policies are imposed appropriately and efficiently. Having a query over a XML secured document tree it’s good that query outcome contains nodes which the user has permissions to in the context he/she can see(Bray & Paoli, 1998,p. 13). Access control denoted by imposed policies must ensure that reference to data by user is indirectly through set of queries on the tree view. It’s proposed in this paper the concept of views as mechanism for XML Access control. Security specification language (SSX) is introduced and policy to rewrite queries of user to impose security constraints (Berchtold& Bohm, 1997, p. 7).
Challenges
Semi structured character of XML data shows that the data is not in normalized formation and makes the job of demining safety views non_trivial.XML data can have replica/missing essentials or omitted attributes. Elements identification is no longer restricted the element value (like documentation in relational model) but depends on the framework, the structure of the path (accessing element from root element) and the children/offspring of the element. Only particular user group can access certain elements contents in same cases in XML, or conditional of visibility based on the value/formation of the elements outer the sub-tree embedded to the element in matter. User groups can also have differing structure for a particular element (Bray & Paoli, 1998, p. 15). Thus Access control in XML should consider nodes structural relationship. The next challenge is the occurrence of numerous policies of access control. It’s expensive in constant data change to really materialize and retain each view that implements a safety design.XML research on access control has deled with some of the above outcomes with differing efficiency and degrees of achievement.
Proposed approaches differ from XML cryptography, access control language, to materialized security views, check method and execute. Latest work by Fan et al. came up with an approach that annotated the security limits on the schema formation and repeat XPath queries issued beside the parent XML document. Security annotation expressiveness is restricted to hiding node/sub-tree principles. Enforcing safety constraints focusing on the structural relationships involving elements, which is at least as vital as the values, remains an open question in the XML background and is one of the core donations of this paper (Doyle & Ferrano, 1998, p. 17)
Motivating scenarios
Reflect on an XML database that holds the university information on the human resource. In the hierarchical formation, the university has several departments (dept) which each has an inventory of employees and a location
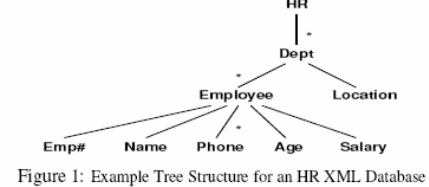
Preliminaries and Problem Definition
Xml data is usually represented as an embedded node labeled tree formation, in which objects (element, attributes and element contents) is represented by nodes and containment relationship represented with edges among objects. Representing information XML schema it uses this popular two languages XML schema and DTDs. XML structure may be represented as tree as in figure 1, with no significant difference among XML schema and a DTD in demonstrating XML schema information as far as safety is concerned (features such as data types are not needed in XML specific features schema for view specification on security).XPath query declarative language on XML documents and is the hub of other difficult Extensible Markup Language (XML) query languages, like X Query. Query requirements can be declared using an X Path expression by locating the node concerned through the course from the parent document to the basics which serve as the source of the sub-tree to be retrieved (Daengdej & Lukose, 1997, p. 18).
XML security view specification
Security Specification Language in support of XML (SSX) WEB SERVICE ONTOLOGIES FOR QOS AND GENERAL QUALITY EVALUATIONS. Ontologies, semantic Web, QoS, quality.
Literature review
There are numerous Quality of Service (QoS) ontologies explicitly known in literature such as FIPA’s; MILO’s and many others. These ontologies are purposely catered to evaluating QoS metrics like bit error rate and contains IT related terms for web service like valid for transport protocol name. Instead, a more universal advance is to stipulate ontology for SLM’s. This advance of demonstrating additional universal contracts is extra aligned with the spirit of Mid-level Ontology for quality (MoQ) since primary premise of TOVE is in that class view at the design of “formal presentation of QoS and other web services constraints. They believe that essential ontologies contain QoS metrics, currency units, measurement methods, measurement units and measurement properties.
Motivating scenarios and competency questions
In common ontological engineering methodology construction of ontology begins with a style form picture of the business state for which ontology systems based will be used on (Stolpmann &Wess, 1998, p. 7). The above statement is known as the motivating scenario. Competency questions are where scenario is parsed status higher rank business questions which ontology system based could be capable to answer (Watson, 1997, p. 8). The example of motivating scenario is when there is time wasting process concerning database queries, emailing reports and editing/building mailing list. Ontology –based systems must be able to answer competency questions like: is this a quality of system requirement? Is this requirement satisfied?
MOQ
Requirements Ontology
The frequently asked question is whether QoS is a prerequisite? This kind of question being very logic, in the above question, reason or logic is determined in the first-order, where: QoS-obligation (Q). Q is a variable and can depict the ID or the name of QoS requirement. QoS requirement is a special kind of a quality requirement, which become a requirement. X [ qos_requirement(Q) _ quality_requirement(Q) _ requirement(Q) ]. (2)From the ID many thing s can be reasoned from the requirement irrespective of its inside, e.g. its formation (structure).
Conclussion
This conclusion involves research work and different topics as depicted in the whole paper. It is proved that a number of the semantic Web Ontologies helpful for assessing QoS are extremely implementation alert. The “round trip time” is one of the ontologies that depicts the germane QoS metrics and may even be strictly combined with Web services habits that permit successful assessment. SHOE or OWL ontology measurement based cannot readily respond to several questions in the design, e.g. is there a series of values that are agreeable? This is because they do more of representing and less of representing QoS (Sengupta, 1998, p. 10). QoS metrics to speak estimate metrics meant for processes of semi-automated business that in fraction but not totally utilize Web services, and in sort to pre-empt possible misunderstandings between Web service requester and provider and there is obviously rate in footing QoS ontologies in ontologies of extra universal superiority concepts or enhancing inter-operation among these groups of ontologies (Kitano &Shimazu, 1996, p. 11).
In relational databases the standard language is SQL (Structured Query Language), but it is so far to create major weight in the SGML world. SQL is present in object-relational and object-oriented databases, while SGML being on the SQL databases. It would be good if implementation of SQL is in SGML systems, and it is not that far. There is a construction of a prototype (model) of the methodology. With the help of XSLT transformations which will be used with implementations and natural and heuristics language programming styles will be implemented with Java TM. Diverse editions of several of these heuristics are being experimented for reverse engineering relational database they will be adapted and improved and the latest heuristics constructed as required with the research proposed. The tool will be tested using the DTDs content management developed for controlling lecture and course content management. It should b done manually to comprehend its actions and how the can be strengthened (Gardingen & Ian Watson, 1998, p. 13)
Categorization is presented for existing models of CBR implementations into three modules and shown how this view leads realistic support for construction and maintaining corporate memories. The universal transformations from an implementation to other, permits for the conversion of current implementations and smooth the progress of the grouping of implementation kinds that convene new and altering task requirements. With the gaining popularity of system of XML and its database, the ability to hide data user groups is significant as making the data present to end users in a friendly and an efficient manner.
XML access control challenges comes in due semi-structured character of the XML document compared to world relational. Structural relationships between attributes/elements are sensitive, not only values of attributes/elements in the XML context. SSX (security view specification language) is proposed in XML for DBAs to indicate the security constraints. Arrangement to study the projected primitives from a formal perspective to determine helpful properties and also do algorithmic study to compute limits for the rewrite algorithm.
References
Allen J. and Patterson D. (1995). ACM PODS: Integration of Case Based Retrieval with a Relational Database System in Aircraft Technical Support. Springer Publishing Group.
Astrahan M. and Chamberlinn D. (1995). Communication of the ACM: Implementation of a Structured English Query Language. International Publishing Group.
Bancilhon F. and Delobel C. (1992). The Story of O2: building an Object-oriented Database Dystem. Morgan Kaufmann Publishers.
Berchtold S. and Bohm C. (1997).ACM PODS: A Cost Model For Nearest Neighbor Search in High-Dimensional Data Space. Springer Publishing Group.
Berman A. and Diaz A. (1999). Data Description by Example. Alpha Research Project Documentation. Web.
Bray A. and Paoli J. (1998). Extensible Markup Language. Foxit Software Company. Web.
Daengdej R. and Lukose D. (1997). How Case-Based Reasoning and Cooperative Query Answering Techniques Support RICAD. Springer Publishing Group.
Doyle M. and Ferrario M. (1998). Technical Report: CBR Net:- Smart Technology Over a Network. Trinity College Dublin.
Elmasri R. and Shamkant B. (1989). Fundamentals of Database Systems. Cummins Publishing Group.
Fernandez I.and Aha D. (1999). Case-Based Problem Solving For Knowledge Management Systems. AAAI Publishing Group.
Gardingen D. and Watson I. (1998). A Web Based Case-Based Reasoning System For HVAC Sales Support: In Applications & Innovations in Expert Systems. Springer Publishing Group.
Garofalakis D. and Gionis A. (2000). XTRACT: A System for Extracting Documents Type Descriptors from XML Documents. International Publishing Group.
Goldfarb S. and Prescod P. (2000). The XML Handbook. Prentice Hall PTR.
Kitano H. and Shimazu H. (1996). The Experience Sharing Architecture: A Case Study in Corporate-Wide Case-Based Software Quality Control. AAAI Publishing Press.
Melton J. and Simon R. (1992). Understanding the New SQL: A Complete Guide. Morgan Kaufmann Publishers.
Purao S. and Storey V. (2000). Reconciling and Cleansing: An Approach to Domain Models. New Working Paper.
Sengupta A. (1998). The Design of Docbase: Toward the Union of Databases and Document Management. Tata McGraw Hill.
Sengupta A. and Dillon A. (1996). A Methodological Overview: Extending sgml to Accommodate Database Functions. JASIS Publishing Group.
Shafer K. (1995). SGML ’95 Conference: creating DTDs via the GB-Engine and Fred. Boston Publishing Group.
Stolpmann M. and Wess S. (1998). Intelligent System for E-Commerce and Support. International Publishing Group.
Watson F. (1997). Applying Case-Based Reasoning: Techniques for Enterprise Systems. Tata McGraw Hill.