Introduction
Bansal et al. (2017) note that methodology must be “judged by how well it informs research purposes, more than how well it matches a set of conventions” (p. 231). This section of the research study examines the appropriate research design for collection and analysis of data. Since the proposed study is focused, the research will be conducted using a quantitative survey of secondary data consisting of official data on trade performance before and projected results after the Brexit (Binham 2017).
Use of quantitative research design was informed by a need to carry out a comprehensive analysis of sector-based data on trade in the UK following the Brexit. Moreover, the researcher will be able to understand the variables in play through a comparative analysis (Battor & Battour 2013). This part of the report will review data from several reputable sources over a period of nine years, that is, from 2010 to 2018 in order to identify any pattern in the performance of trade before and after the Brexit vote.
Research Design
Researchers have numerous modes of data collection and analysis at their disposal. The method of data collection selected depends on the availability of information, finance, and time. Some of the widely used methodologies include triangulation, surveys, and case studies. Currently, there is limited information about the link between Brexit and performance of trade in the UK. Additionally, the existing data elucidate limited information about the trade industry trends.
Thus, to come up with general findings, there is a need to rely on triangulation method. The research will be performed using quantitative research approach by undertaking focused survey of published data on trade from the government of the UK website and other formal organizations dedicated to trade performance analysis (Blaxter, Hughes & Malcolm 2013). The rationale for selecting quantitative research was informed by the need to comprehend the dynamics around trade performance in the UK market before and after the Brexit vote in order to predict the future trend (Batsaikhan, Kalcik, & Schoenmaker 2017).
Moreover, this approach will enable the researcher to carry out explicit analysis of collected data using different integrated tools such as ANOVA and regression among others to verify the assumption limits and error margin. Use of the quantitative research approach will also facilitate a comprehensive understanding of the existing relationship between variables of trade and how they react to Brexit (Bloom 2014). This means that the researcher will be in a position to study these attributes through observation of trade trends from data mined from different official sites. The quantitative methodology will also be used in data analysis in comparison of trade performance by integrating analytical tools such as correlation and regression (Bryman & Bell 2015). It is expected that these tools will facilitate an accurate establishment of trends from data collected.
Selection of Dependent and Independent Variables
Under trade performance, the researcher focused on stock returns of 30 companies within the UK in order to study their performance under the period of study. Isolation of stock returns will make the analysis more focused and easy to follow for the thirty organizations. Moreover, the stock return is a strong indicator of positive or negative trade performance and organizational and industry levels (Bloom, Draca, & Reenen 2016). This means that stock return is the dependent variable while variations in financial performance will be the independent variable.
Sample Selection and Sample Size
The researcher intends to use focused convenience sampling by focusing on three reputable sites in data mining in order to establish the trend in trade performance in the UK over a period of nine years. Specifically, the samples will be picked from the World Bank, International Monetary Fund (IMF), and the UK government’s publications. Moreover, the researcher will also review existing empirical literature from reputable institutions and individual authors to confirm the trends from the final inferences (Daft & Marcic 2016).
The rationale for selecting the focused convenience sampling approach was the need to save time as opposed to primary research, which would have taken a longer period to process (Denscombe 2015). Moreover,a convenient sampling of the secondary data would guarantee accurate results since different sources will be consulted (Egger et al. 2015). In generating the sample size for the proposed study, the researcher opted to use the formulae created in 1972 to ensure research dependability as explained below (Irwin 2015). Specifically, the research will consider the performance of 30 firms before and after the Brexit for a period of nine years.
n=N/ (1+N (e2))
Where:
n = sample size
N= Target population
e= Degree of freedom
n=30/ (1+30*0.052)
n=30/1.075
n= 27.9
As explained by the Central Limit Theorem, a sample size above 25, as is the case with the proposed study, ensures that the X-Bar is normally distributed across the samples, irrespective of the population shape or other dynamics (García-Herrero & Xu 2016). Therefore, the proposed sample size of 27.9 will be ideal for the research study.
Analysis Methods
Data analysis
Secondary data collected from different sites and publications will be coded individually and then passed through the Statistical Package for Social Sciences (SPSS). During coding, the researcher will generate cross-tabulation to perform a comparative analysis of the existing association or correlation between trade performance in the UK before and after the Brexit vote. In order to quantify the relationship between the independent and dependent variable, the researcher will carry out a regression analysis in addition to use of charts, figures, and tabular representation of the research results (Guiso, Sapienza, & Zingales 2015). During the regression analysis, softwares such as Excel, Google Docs, and eViews will be integrated on a need basis.
Proposed conceptual framework using Cohen’s formula
This research will be based on evaluation methodology through the application of the Cohen’s d formula in calculating the effect sizes of the study and a Comprehensive Meta-Analysis formula. The Cohen’s d formula is summarized as
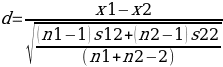
Where x¹ and x² are mean scores while n¹ and n² are sample sizes. The s¹² and s²² are the variances of experimental and control groups. According to Bryman and Bell (2015), for quasi-experimental and experimental pretests, the posttest would mitigate any selection bias. Thus, the developed comprehensive Meta-analysis formula is;
ESPre/Post Test Two Groups = (X1 Post – X1 Pre) – (X2 Post – X2 Pre) / SDPost
Where X1 Post and X1 Pre are experimental groups mean scores for a posttest and pretest. The X2 Post and X2 Pre are control group mean scores for the pretest and posttest. The SDPost was computed as follows:
SDPost= (n2Post – 1)s22Post + (n1 Post – 1) s21Post/ (n2Post + n1 Post-2)
Where n1 Post and n2Post are experimental and control group sample sizes. The s21Post and s22Post are experimental and control group variances in the posttest (Bryman & Bell 2015). Therefore, the effect-size was integrated by the use of sample weights to derive a Hedge’s g as;
Proposed regression model
Reviewing the existing correlation between trade performance and Brexit, the researcher will use ordinary least square regression as explained below.
Y = α + β1X1
Where,
Y = Stock Return (dependent variable).
α =Value of Y at the point where explanatory variables’ values are zero.
β =Parameter indicating average alteration in Y; associated with each unit alternation in variable X.
X= Independent Variable.
In relation to the UK trade performance before and after the Brexit vote, X1 will represent the ratio of changes in organization performance (Bryman & Bell 2015).
Analysis of Variance (ANOVA)
Another important instrument that will be used in the research study is the analysis of variance (ANOVA) to pinpoint statistical patterns in the secondary data collected. The two elements of ANOVA analysis are means of stock return variation (xi-x)² and changes in organizational financial performance (xij-xi)² (Bryman & Bell 2015). Thus, the proposed null and alternative hypotheses for the ANOVA analysis are; Null hypothesis Ho: µ1 = µ2
The null hypothesis implies that the mean of the selected sample population on stock return performance before and after the Brexit vote is equivalent to the mean for the entire population segment.
Alternative hypothesis Ho: µ1 ≠ µ2
The alternative hypothesis implies that the mean of the selected sample population on stock return performance before and after the Brexit vote is not equivalent to the mean for the entire population segment.
From the above hypotheses, the null hypothesis will be rejected when the F-calculated is bigger compared to the F-critical at 99% confidence interval. Blaxter, Hughes and Malcolm (2013), note that ANOVA instrument is significant in establishing the difference in mean of a data set collected through disintegrated variations. In relation to this research study, the analysis of variance instrumentation will be used to present and quantify observable statistical variations between means of each data set as explained below.
The confidence interval in this research study will be estimated at 99%.
Sample statistic + Z value * standard error / √n
b1 = 7.1175 ± 2.57 * 0.9631 / √133
= 7.1175 ± 2.57 * 0.9631 / 11.5326
= 7.1175 ±0.2146
= 6.9029 ≤ b1 ≤ 7.3321
At 95%
b1 = 7.1175 ± 1.96 * 0.9631 / √133
= 7.1175 ± 1.96 * 0.9631 / 11.5326
= 7.1175 ± 0.1635
= 6.954 ≤ b1 ≤ 7.281
At 90%
b1 = 7.1175 ± 1.64 * 0.9631 / √133
= 7.1175 ± 1.64 * 0.9631 / 11.5326
= 7.1175 ± 0.1368
= 6.981 ≤ b1 ≤ 7.254
From the above computations, the estimated confidential interval is at 6.981 ≤ b1 ≤ 7.254 of 90%, 6.954 ≤ b1 ≤ 7.281 of 95%, and 6.9029 ≤ b1 ≤ 7.3321 of 99%. These calculation results suggest that confidential interval estimates increase as interval levels decrease when all other factors are held constant. As noted by Kothari (2013), “application of the ANOVA is focused on quantifying the existing variance in different sets of data by disintegrating the differences existing in the sets for each transcribed group” (p. 56). Therefore, in this research study, the ANOVA analysis will present the data sets mean differences for each organization from the perspective of stock return ratio (see appendix 1).
Dependability and reliability
The researcher will guarantee dependability by providing detailed, sequential, and clear data collection, description, and analysis. Specifically, the proposed research design will ensure that data analysis and interpretation is congruent with the research questions. Moreover, the theoretical construct and different analytical frameworks will facilitate a smooth transition in the inferences within meaningful parallelism for the secondary data sources (Kothari 2013). In addition, the researcher is equipped with necessary scientific research skills to ensure complete professionalism and a neutral approach to data analysis and interpretation.
Generalisability and Vigour
The secondary survey research sample selected presents scientific, verifiable, and clear criteria for tracking stock performance trends before and after the Brexit vote. On the basis of the above strengths, the proposed sample size is a representation of the space and scope at specific intervals as discussed before. Moreover, the representative sample will give room for a comparative analysis, especially within the complex quantitative design selected (Trommer 2017). As a result, it will be possible to test the degree of biasness and accuracy. Therefore, the secondary survey will be a hallmark of accurate population representation and strength of the proposed study.
Ethical considerations
During the entire period of study, the researcher intends to uphold different ethical principles relevant to the scope and nature of the research. For instance, the researcher will request for data from different organizations through a formal letter or email, entailing the reasons for the study. Moreover, the researcher will attach the university letter head in order to be accorded necessary assistance.
With adequate experience and training in data collection and analysis, the researcher will not face major challenges in coding and transcribing the raw statistics. The credibility of the study will be enhanced by integrating distinct quantitative design in gathering, analysis, and interpretation of collected data to create an accurate inference (Yu et al. 2017). The aspect of transferability in the collected data and results will be made possible by using a relatively large sample, which is representational of the data population.
During the data collection phase of this study, the researcher will strive to uphold ethics appertaining to scientific research. Authorization for conduction of this study will be sought from relevant authorities to ensure transparency. The researcher has prior training and experience in data collection and analysis at the college level. Credibility is enhanced by adopting distinct quantitative and qualitative approaches to gathering data and reporting findings. Transferability of the results is theoretically possible by gaining a sufficiently large sample that will be representative of the data population. The researcher will integrate the Scientific Research Code of Ethics (Bryman & Bell 2015).
Methodology Justification
The use of a quantitative research design was necessary since the study aims at understanding the existing correlation and variations in stock return for thirty companies within the UK market before and after Brexit vote. This means that quantitative analysis creates an ideal environment for comparative analysis of dependent and independent variables (Liu, Shang & Han 2017). The proposed study will be concentrated in selected sectors (Oliver 2016). Thus, the scope of this study will encompass examination of the research magnitude from the results addressing each research problem.
Potential Biases and Minimisation
Since the researcher will depend on available and published secondary data, it might be difficult to prove the authenticity of some data, especially in instances of missing information (Smetana 2016). In order to minimise this bias, the study will concentrate only on official published data in addition to consulting other sources for authenticity (Sampson 2016). Since substantial data was collected from quantitative research, there is the possibility of bias besides inaccurate data on trade performance (Kothari 2013). The sample space only consisted of thirty organizations, thus, the research might end up with a relatively shallow data set (Bryman & Bell 2015). The collection of accurate data was difficult since some authorities did not have updated information (Matthews 2016). Therefore, the researcher was unable to compare the existing and past stock returns in some instances (Smith 2017). However, this challenge was minor and did not affect the outcome.
The researcher will subject each quantitative data set to transcription to ensure consistency and dependability. For instance, each data set will be coded to reduce generalization bias (Bryman & Bell 2015). Moreover, the researcher has adequate training on professionalism and will remain neutral in presenting results. Thematic and content analyses will also be closely observed to ensure that findings fall within the context of the study (Sherif 2018). In order to minimize biases associated with quantitative data, the research will use official data from government institutions and only refer to other sources to confirm the existing trend (Office for National Statistics 2015).
Expected results
It is expected that the Brexit have an indirect and direct impact on stock returns with reference to the performance of trade within the UK (Kraft 2013; Rojas-Romagosa 2016). The collected published data indicated that trade has increased steadily in the last nine years, especially in the financial sector (Mason 2017). The rationale for using two sectors in the analysis was informed by the segregated nature of data from other sectors (Singh & Singh 2014).
Resources and costs involved
Resources
The data collection and analysis will be based on three reputable sources, that is, the UK government, IMF, and World Bank publications. Moreover, the researcher will consult other past case study researches, financial journals, academic books, and online finance websites such as yahoo.com, aastocks.com, reuters.com, google.com, and bloomberg.com (Saunders, Lewis & Thornhill 2016). These sites are authentic since most of the materials in them are from reputable firms. The academic journals to be used in this research paper will be selected from academic and authentic financial sites such as Pro Quest, Harvard Business Review, Emerald, ABI, google.com, and BNU e-database.
Costs
The cost of the entire study is expected to be less than $200 since it is focused on secondary data.
Conclusion
The evaluation methodology has been selected to draw inferences and conclusions in this research study. The quantitative research design was chosen as the primary blue-print in data analysis and interpretation, including the significance of observation, quality of context evaluation, and proactive use of human interpretation. The proposed dependent and independent variables are stock returns and ration of financial performance before and after the Brexit vote for a cumulative period of nine years running concurrently from 2010 to 2018. The small sample space might result in biases from limited insight.
However, the research will probe and code each data set to guarantee consistency and accuracy in presentation and analysis. The rationale for selecting a quantitative research design was informed by the need to establish the current insight in stock returns and relate them to the trade trend from secondary data over a period of nine years. The secondary data will be collected mainly from reputable sources, which are the government of UK publications, World Bank, and IMF. Other sources such as financial journals, dedicated institutions, and books will be consulted in the analysis. The expected findings based on the literature review are that Brexit will have the direct and indirect impact on trade performance.
References
Bansal, H, Eldridge, J, Haider, A, Knowles, R, Murray, M, Sehmer, L & Turner, D 2017, ‘Shorter interviews, longer surveys’, International Journal of Market Research, vol. 59, no. 2, pp. 221-238.
Batsaikhan, U, Kalcik, R & Schoenmaker, D, 2017, Brexit and the European financial system. Bruegel Policy Contribution, Bruegel, Brussels, Belgium.
Battor, M & Battour, M, 2013, ‘Can organizational learning foster customer relationships? Implications for performance’, The Learning Organization, vol. 20, no. 5, pp. 279-290.
Binham, C, 2017, Bank of England calls for clarity over derivatives post-Brexit. Web.
Blaxter, L, Hughes, C & Malcolm, T, 2013, How to research, Open University Press, Berkshire, UK.
Bloom, N, 2014, ‘Fluctuations in uncertainty’, Journal of Economic Perspectives, vol. 28, no.2, pp. 153–76.
Bloom, N, Draca, M & Reenen, J, 2016, ‘Trade induced technical change? The impact of Chinese imports on innovation, IT and productivity’, Review of Economic Studies, vol. 83, no. 1, pp. 87–117.
Bryman, A & Bell, E, 2015, Business research methods, 4th edn, Oxford University Press, Oxford, UK.
Daft, R & Marcic, D, 2016, Understanding management, 10th edn, Cengage Learning, London, UK.
Denscombe, M, 2015, Ethics: ground rules for good research, Open University, Buckingham, UK.
Egger, P, Francois, J, Manchin, M & Nelson, D, 2015, ‘Non-tariff barriers, integration and the transatlantic economy’, Economic Policy, vol. 30, no.6, pp. 539-584.
García-Herrero, A & Xu, J, 2016, What consequences would a post-Brexit China- UK trade deal have for the EU?. Web.
Guiso, L, Sapienza, P & Zingales, L, 2015, ‘The value of corporate culture’. Journal of Financial Economics, vol. 117, no. 1, pp. 60-76.
Irwin, G, 2015, Brexit: the impact on the UK and the EU, Global Council, London, UK.
Kothari, R, 2013, Research methodology: methods and techniques, 3rd edn, New Age International, New Delhi, India.
Kraft, M. E, 2013, Public policy: Politics, analysis, and alternatives, SAGE, New York, NY.
Liu, J, Shang, J & Han, J, 2017, Phrase mining from massive text and its applications, Morgan & Claypool Publishers, London, UK.
Mason, J, 2017, Qualitative researching, 3rd edn, SAGE, London, UK.
Matthews, A, 2016, ‘The potential implications of a Brexit for future EU agri-food policies’, EuroChoices,vol. 15,pp. 17-23.
Office for National Statistics 2015, How important is the European Union to UK. Web.
Oliver, T, 2016, ‘The world after Brexit: From British referendum to global adventure’, International Politics, vol. 53, no.6, pp. 689-707.
Rojas-Romagosa, H, 2016, Trade effects of Brexit for the Netherlands,CPB, Netherlands Bureau for Economic Policy Analysis.
Sampson, T, 2016, ‘Dynamic selection: An idea flows theory of entry, trade, and growth’, Quarterly Journal of Economics, vol. 131, no. 1, pp. 315–80.
Saunders, M, Lewis, P & Thornhill, A, 2016, Research methods for business student, 7th edn, Pearson Education, Harlow, UK.
Sherif, V, 2018, ‘Evaluating pre-existing quantitative research data for secondary analysis’, Forum: Qualitative Social Research, vol. 19, no.2, pp. 56-67.
Singh, H & Singh, B, 2014, ‘Total quality management: Today’s business excellence strategy’, International Letters of Social and Humanistic Sciences, vol. 12, no. 32, pp. 188-196.
Smetana, M, 2016, ‘Stuck on disarmament: The European Union and the 2015 NPT review conference’, International Affairs, vol. 92, no.1, pp. 137-152.
Smith, S, 2017, Practical tourism research, 2nd edn, CABI, New York, NY.
Trommer, S, 2017, ‘Fragmentation and decline? The UK and the global trading system after Brexit’, Renewal: A Journal of Labour Politics, vol. 25, no.3, pp. 101-110.
Yu, W, Elleby, C, Lind, K. M. H & Thomsen, M. N, 2017, Modeling the potential impacts of two BREXIT scenarios on the Danish agricultural sectors, Department of Food and Resource Economics, University of Copenhagen, IFRO Report, No. 260.
Appendix 1: Data correlation
Part 1: Correlations
[DataSet2]
Part 2: Regression
[DataSet2]